
Pythonでデータ分析や機械学習をするとき、効率的にデータを扱うことができるpandasを使用します。
pandas.DataFrameのデータ構造を一目見ておくと、簡単にデータ加工ができるようになりますよ。
pandas.DataFrame(データフレーム)の構造
pandas.DataFrameの構造を見てみましょう。
pandas.DataFrameは、3つの要素で構成されています。
・インデックス(行インデックス)
・カラム(列インデックス)
・データ

pandas.DataFrameは、「インデックス」と「カラム」で構成された格子状の箱に、データが格納されています。
データの格納場所は、「インデックス」と「カラム」で指定するので、2次元のデータと呼ばれます。
pandas.Series(シリーズ)の構造
pandas.Seriesの構造を見てみましょう。
pandas.Seriesは、2つの要素で構成されています。
・インデックス
・データ

pandas.Seriesは、「インデックス」が割り当てられた箱の塊に、データが格納されています。
データの格納場所は、「インデックス」だけで指定するので、1次元のデータと呼ばれます。
また、pandas.Seriesには、「カラム」がありませんが、「Name属性」を持つことができます。
pandas.DataFrameとpandas.Seriesの関係
pandas.DataFrameとpandas.Seriesの構造を確認しました。
共通点は、「インデックス」と「データ」の2つの要素を持っていること。
相違点は、pandas.DataFrameには「カラム」があり、pandas.Seriesは「Name属性」を持っていること。
両者の関係を図示すると、以下のようになります。
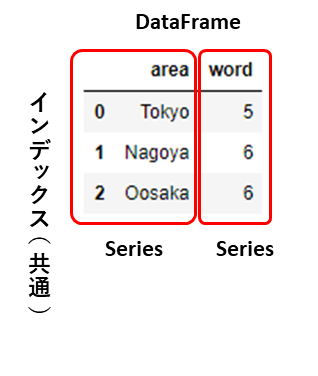
pandas.DataFrameの各列は、pandas.Seriesで構成されています。
つまり、pandas.DataFrameは、pandas.Seriesの集合体なのです。
pandas.DataFrameから取り出したpandas.Seriesの「Name属性」は、元のpandas.DataFrameの「列名」です。
逆に、pandas.Seriesからpandas.DataFrameを作成すると、「Name属性」が、pandas.DataFrameの「列名」になります。
実例で確認
サンプルデータ
3行2列のpandas.DataFrameを作成します。
列名「area」は、都市名
列名「word」は、都市名の文字数
import pandas as pd
df_city = pd.DataFrame([['Tokyo', 5], ['Nagoya', 6], ['Oosaka', 6]],
columns=['area', 'word'])
df_city area word
0 Tokyo 5
1 Nagoya 6
2 Oosaka 6pandas.Seriesの取得
列名「area」を取り出します。
s_area = df_city['area']
s_area0 Tokyo
1 Nagoya
2 Oosaka
Name: area, dtype: object
type関数を使用して、取り出したオブジェクトの型を確認します。
type関数は、引数に渡したオブジェクトの型を返します。
type(s_area)pandas.core.series.Seriespandas.DataFrameから「列名」を指定して取得したオブジェクトは、pandas.Seriesと確認できました。
1列のpandas.DataFrameの取得
pandas.DataFrameから列の取得は、
・データフレーム[列名] ・・・ pandas.Seriesを取得
・データフレーム[[列名]] ・・・ pandas.DataFrameを取得
となります。
列名「area」だけのpandas.DataFrameを取り出します。
df_area = df_city[['area']] # 列名「area」をリストとして指定
df_area area
0 Tokyo
1 Nagoya
2 Oosaka
type関数を使用して、取り出したオブジェクトの型を確認します。
type(df_area)pandas.core.frame.DataFramepandas.DataFrameから「列名のリスト」を指定して取得したオブジェクトは、pandas.DataFrameと確認できました。
1列のDataFrameは、Seriesとは違うもの?
1列のDataFrameと、Seriesについてまとめると、以下のようになります。
| データ型 | 次元 | カラム | Name属性 | |
| 1行のDataFrame | pandas.core.frame.DataFrame | 2次元 | あり | なし |
| Series | pandas.core.series.Series | 1次元 | なし | あり |
設問の答えは、構造が違う「1列のDataFrame」と「Series」は別物です。
実例で確認
あまりピンと来ないと思いますので、実例を見てみましょう。
1列のDataFrame のデータを取り出します。
df_area.valuesarray([['Tokyo'],
['Nagoya'],
['Oosaka']], dtype=object)
データの形状も確認します。
df_area.values.shape(3, 1)3行1列のnumpy.ndarrayです。
オブジェクトの型は、type関数で確認してみてください。
次は、Seriesです。
s_area.valuesarray(['Tokyo', 'Nagoya', 'Oosaka'], dtype=object)
データの形状も確認します。
s_area.values.shape(3,)Seriesは1次元配列なので、要素数が返ってきています。
これは、要素数3のnumpy.ndarrayです。
データの形状が違うので、要素の取り出し方も異なります。
Seriesから1つ目の要素を取り出してみます。
s_area.values[0]'Tokyo'1つ目の要素「Tokyo」が取得できました。
1列のDataFrameから1つ目の要素を取り出してみます。
df_area.values[0]array(['Tokyo'], dtype=object) 1つ目の要素「リスト[Tokyo]」が取得できました。
要素「Tokyo」を取り出すためには、locやilocを使用して行も指定します。
df_area.iloc[0].values[0]'Tokyo'pandas.DataFrameは、「インデックス」と「カラム」でデータの格納場所を指定します。
1列のDataFrameでも、0行0列のデータとして指定する必要があります。
2列のpandas.DataFrameの方が、カラムを指定する感じがつかめると思います。
df_city.valuesarray([['Tokyo', 5],
['Nagoya', 6],
['Oosaka', 6]], dtype=object)各行に2つの要素があります。
要素「Tokyo」は、0行0列から取り出します。
df_city.iloc[0].values[0]'Tokyo'まとめ
- pandas.DataFrameが、3つの要素で構成されていることがわかった
- pandas.Seriesが、2つの要素で構成されていることがわかった
- pandas.DataFrameは、pandas.Seriesの集合体だとわかった
pandas.DataFrameとpandas.Seriesの違いは、構造の違いにありました。
1次元のpandas.Seriesを使用するメリットには、シンプルな構造で扱いやすい点があると思います。
記述するコードの量が少なくなるのも良いですね。

