
モデルを構築する過程で、モデルの精度に寄与する特徴量を見つけることが大切です。
LightGBMでは、「特徴量の重要度」が簡単に出力できます。
ただ、初期値のまま使うのはもったいないので、パラメータを設定して使いましょう。
特徴選択を行う理由
モデルの精度は、適切なデータの特徴量を加えると向上します。
逆に、ノイズとなる特徴量があると、精度が落ちてしまいます。
LightGBMやXGBoostのような「GBDT」は、ノイズとなる特徴量を追加しても精度が落ちづらいと言われていますが、不要な特徴量は除いておくことに、次のメリットがあります。
・メモリの節約
・計算時間の縮減
重要度の少ない特徴量でも、取り除くと、精度が落ちることがあります。
モデルの学習に使用しているので、わずかでも精度向上に貢献しているかもしれませんが、ホールドアウトしたテストデータでも役に立つとは限りません。
時間は、重要度の高い特徴量の検証に使った方が、得られる効果が高いと思います。
重要度の少ない特徴量を惜しむより、整理することに、メリットがあるでしょう。
特徴量の重要度
LightGBMの「特徴量の重要度(feature_importance)」には、計算方法が2つあります。
・頻度: モデルでその特徴量が使用された回数(初期値)
・ゲイン: その特徴量が使用する分岐からの目的関数の減少
LightGBMでは、「頻度」が初期値に設定されています。
しかし、「ゲイン」の方が、精度を向上させる面では、どの特徴量が重要か表していると言えます。
「目的関数の減少」の情報を見逃しているのは、とても「もったいない」です。
公式サイトはこちら
使用例
次の記事で解説したサンプルコードで「feature_importance」を使ってみます。
【Python覚書】LigthGBMで多値分類問題を解いてみる
とりあえず、動かしてみたい方に、サンプルコードは以下のとおり。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
# iris データセットを読み込む
iris = datasets.load_iris()
X = iris['data']
y = iris['target']
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X = pd.DataFrame(X, columns=iris['feature_names'])
# カテゴリー変数を作成
# sepal(がく)の面積から4区分のカテゴリーを作成
df_X['sepal_cat'] = df_X['sepal length (cm)'] * df_X['sepal width (cm)']
df_X['sepal_cat'] = pd.qcut(df_X['sepal_cat'], 4, labels=False)
df_X['sepal_cat'] = df_X['sepal_cat'].astype('category')
# カテゴリー変数を作成
# petal(花びら)の面積から4区分のカテゴリーを作成
df_X['petal_cat'] = df_X['petal length (cm)'] * df_X['petal width (cm)']
df_X['petal_cat'] = pd.cut(df_X['petal_cat'], 4, labels=False)
df_X['petal_cat'] = df_X['petal_cat'].astype('category')
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y,
test_size=0.2,
random_state=0,
stratify=y)
# 学習データを、学習用と検証用に分ける
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train,
test_size=0.2,
random_state=1,
stratify=y_train)
# カテゴリー変数
categorical_features = {*sorted(['sepal_cat', 'petal_cat'])}
# データを格納する
# 学習用
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features,
free_raw_data=False)
# 検証用
lgb_eval = lgb.Dataset(X_eval, y_eval, reference=lgb_train,
categorical_feature=categorical_features,
free_raw_data=False)
# パラメータを設定
params = {'task': 'train', # 学習、トレーニング ⇔ 予測predict
'boosting_type': 'gbdt', # 勾配ブースティング
'objective': 'multiclass', # 目的関数:多値分類、マルチクラス分類
'metric': 'multi_logloss', # 分類モデルの性能を測る指標
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.02, # 学習率(初期値0.1)
'num_leaves': 23, # 決定木の複雑度を調整(初期値31)
'min_data_in_leaf': 1, # データの最小数(初期値20)
}
# 学習
evaluation_results = {} # 学習の経過を保存する箱
model = lgb.train(params, # 上記で設定したパラメータ
lgb_train, # 使用するデータセット
num_boost_round=1000, # 学習の回数
valid_names=['train', 'valid'], # 学習経過で表示する名称
valid_sets=[lgb_train, lgb_eval], # モデル検証のデータセット
evals_result=evaluation_results, # 学習の経過を保存
categorical_feature=categorical_features, # カテゴリー変数を設定
early_stopping_rounds=20, # アーリーストッピング
verbose_eval=10) # 学習の経過の表示(10回毎)
# 最もスコアが良いときのラウンドを保存
optimum_boost_rounds = model.best_iteration
# テストデータで予測
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy の計算
accuracy = sum(y_test == y_pred_max) / len(y_test)
print('accuracy:', accuracy)
# feature importanceを表示
importance = pd.DataFrame(model.feature_importance(), index=df_X.columns, columns=['importance'])
display(importance)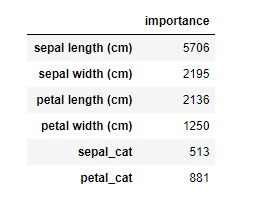
頻度: feature_importance(importance_type = ‘split’)
# feature importanceを表示
importance = pd.DataFrame(model.feature_importance(importance_type='split'), index=df_X.columns, columns=['importance'])
importance = importance.sort_values('importance', ascending=False)
display(importance)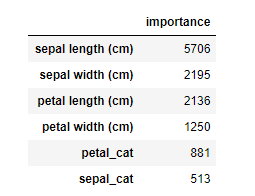
feature_importanceに、「頻度(初期値)」のパラメータ「importance_type = ‘split’」を設定しています。
データフレームに入れた値は、「importance」で降順に並び替えていますが、各値は同じです。
ゲイン: feature_importance(importance_type = ‘gain’)
# feature importanceを表示
importance = pd.DataFrame(model.feature_importance(importance_type='gain'), index=df_X.columns, columns=['importance'])
importance = importance.sort_values('importance', ascending=False)
display(importance)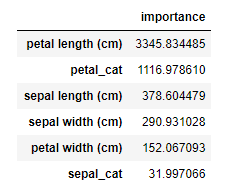
feature_importanceに、「ゲイン」のパラメータ「importance_type = ‘gain’」を設定しています。
データフレームに入れた値は、「importance」で降順に並び替えています。
「ゲイン」での重要度を見ると、目的関数の減少に役立つ特徴量がよくわかります。
まとめ
「特徴量の重要度」は、初期値のまま使うと、決定木の分岐を使用した数を計算します。
目的変数を減少させる特徴量の重要度は、「ゲイン」を計算する必要があるので、忘れないようにパラメータを設定しましょう。

