
課題の設定
国内の分析コンペサイトにて、マルチクラス分類のコンペが開催されていたので、LightGBMの使い方をまとめておきたいと思います。
データセットの読込から学習過程の可視化まで、以下の作業をやってみます。
分析は、一番シンプルなIrisデータセットを使用します。
- データセットの読み込み
- 特徴量の作成
- パラメータの設定
- モデルの作成
- モデルの評価
- 学習過程の可視化
使用するライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFoldLightGBMは、インストールされている前提でインポートしています。
インストールガイドは、以下(英語)にあります。
・Installation Guide
なお、インストール方法は、先人のブログがたくさんありますので、自身のPC環境に合った方法を探してみてください。
データセット
# iris データセットを読み込む
iris = datasets.load_iris()
X = iris['data']
y = iris['target']
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X = pd.DataFrame(X, columns=iris['feature_names'])sklearn.datasetsからirisデータセットを読み込みます。
読み込んだデータは、Bunch型のオブジェクトです。
print(type(iris))
>> <class 'sklearn.utils.Bunch'>Bunch型は、辞書型のサブクラスです。
辞書型と同じように、iris[‘key’]や、iris.keyで、要素を取りだすことができます。
なお、ドット表記の事例が多いようですが、この記事では、要素(特徴量)へのアクセスを明示するために、角括弧([ ])を使用します。
keyの一覧は、辞書のkeys()メソッドで取り出せます。
print(iris.keys())
>> dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
ここでは、説明変数iris[‘data’]を変数X、目的変数iris[‘target’]を変数yに格納しています。
変数Xは、各要素(特徴量)の名称iris[‘feature_names’]をカラム名として、pandas.DataFrameに格納することで、pandasの強力なメソッドが使用できるようにします。
特徴量の作成
説明変数を確認します。
先頭の5行を取得します。
df_X.head()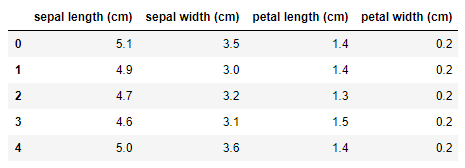
pandasのデータ型dtypesを取得します。
df_X.dtypes
>>
sepal length (cm) float64
sepal width (cm) float64
petal length (cm) float64
petal width (cm) float64
dtype: object
説明変数は、4つで、float64型の数値変数のみです。
説明の都合上、カテゴリー変数があるとよいので、2つ作成します。
# カテゴリー変数を作成
# sepal(がく)の面積から4区分のカテゴリーを作成
df_X['sepal_cat'] = df_X['sepal length (cm)'] * df_X['sepal width (cm)']
df_X['sepal_cat'] = pd.qcut(df_X['sepal_cat'], 4, labels=False)
df_X['sepal_cat'] = df_X['sepal_cat'].astype('category')# カテゴリー変数を作成
# petal(花びら)の面積から4区分のカテゴリーを作成
df_X['petal_cat'] = df_X['petal length (cm)'] * df_X['petal width (cm)']
df_X['petal_cat'] = pd.cut(df_X['petal_cat'], 4, labels=False)
df_X['petal_cat'] = df_X['petal_cat'].astype('category')カテゴリー変数の特徴量として、「sepal_cat」と「petal_cat」を作成しました。
それぞれ、アヤメの「がく」と「花びら」の長さと幅を掛けた面積です。
pd.qcutとpd.cutは、ビンニング処理です。
連続値を4区分のカテゴリーに分けた離散値に変換しています。
・qcut() : 区分内の「値の数が同じ」になるように分割
・cut() : 最大値と最小値の間を「等間隔に分割した区分」内にある値の数
これで、説明変数は、6つの特徴量になりました。
モデルの作成
モデルの作成を、次のステップで行います。
1. 特徴量と目的変数を、LightGBM用のデータ構造に変換
2. ハイパーパラメーターの設定
3. 学習の実行
特徴量と目的変数を、LightGBM用のデータ構造に変換
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y,
test_size=0.2,
random_state=0,
stratify=y)
# 学習データを、学習用と検証用に分ける
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train,
test_size=0.2,
random_state=1,
stratify=y_train)
# カテゴリー変数
categorical_features = {*sorted(['sepal_cat', 'petal_cat'])}
# データを格納する
# 学習用
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features,
free_raw_data=False)
# 検証用
lgb_eval = lgb.Dataset(X_eval, y_eval, reference=lgb_train,
categorical_feature=categorical_features,
free_raw_data=False)ホールドアウト法(holdout cross-validation)
ホールドアウト法を使って、データセット全体を3つに分割します。
・学習データ
1. 学習用: モデルの学習に使用
2. 検証用: ハイパーパラメーターの調整に使用
・テストデータ: モデルの評価に使用

〇データセットの定義(呼び方、表記)について
今回、データセットを3つに分割しました。
この3つのデータセットは、出典によって、様々な表記がされているので注意が必要です。
一例ですが、以下のような感じです。
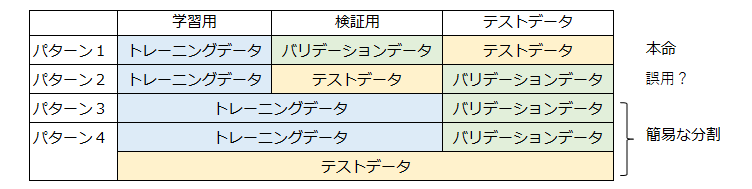
この記事は、パターン1に沿った表記にしています。
パターン3やパターン4は、トレーニングデータセットとテストデータセットの分割をしていないケースです。
テストデータセットを、トレーニングデータセットから独立させないで、バリデーションデータなどでモデルを評価します。
とりあえずモデルを動かしてみたい場合などの、簡易な取り扱いです。
〇train_test_split(df_X, y, test_size=0.2, random_state=0, stratify=y)
データ「df_X,y」をテストデータが20%になるように分割します。
パラメータ「random_state=0」は、分割に使用する乱数の初期値を固定します。
データセットの分け方によって、モデルの性能が上下するので、同じデータになるようにしています。
パラメータ「stratify=y」は、データ「y」の各要素が同じ数になるようにします。
今回は、分類を行うので、目的変数の分布が同じになるようにしています。
カテゴリー変数
LightGBMには、カテゴリー変数をパラメータで指定した場合に、勾配によって最適な分岐を行う機能があると書いてあります。
カテゴリー変数をcategorical_featuresに格納します。
以下のように、シンプルにカテゴリー変数をリストにすればよいです。
categorical_features = ['sepal_cat', 'petal_cat']サンプルコードは、Jupyter notebookのwarningが消えるように書いています。
categorical_features = {*sorted(['sepal_cat', 'petal_cat'])}内側から、解説すると、
・リストに、カテゴリ変数の列名を格納
・リストの要素をソート(並び替え)
・*(アスタリスク)で、リストをアンパック(分解して渡す)
・{*リスト}で、リストの要素でsetオブジェクトを生成(要素の重複なし)
LightGBM用のデータセット
lgb.Dataset()メソッドで、データセットを作成します。
free_raw_data=Falseについては、以下をご覧ください。
公式ドキュメント LightGBM FAQ
ハイパーパラメーターの設定
# パラメータを設定
params = {'task': 'train', # 学習、トレーニング ⇔ 予測predict
'boosting_type': 'gbdt', # 勾配ブースティング
'objective': 'multiclass', # 目的関数:多値分類、マルチクラス分類
'metric': 'multi_logloss', # 分類モデルの性能を測る指標
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.02, # 学習率(初期値0.1)
'num_leaves': 23, # 決定木の複雑度を調整(初期値31)
'min_data_in_leaf': 1, # データの最小数(初期値20)
}今回は、多値分類を行うので、objectiveに「multiclass」を設定します。
評価関数metricは、「multi_logloss」を使用します。
learning_rateなどは、グリッドサーチなどで最適化を図るとよいです。
学習の実行
# 学習
evaluation_results = {} # 学習の経過を保存する箱
model = lgb.train(params, # 上記で設定したパラメータ
lgb_train, # 使用するデータセット
num_boost_round=1000, # 学習の回数
valid_names=['train', 'valid'], # 学習経過で表示する名称
valid_sets=[lgb_train, lgb_eval], # モデル検証のデータセット
evals_result=evaluation_results, # 学習の経過を保存
categorical_feature=categorical_features, # カテゴリー変数を設定
early_stopping_rounds=20, # アーリーストッピング
verbose_eval=10) # 学習の経過の表示(10回毎)
# 最もスコアが良いときのラウンドを保存
optimum_boost_rounds = model.best_iteration
num_boost_round=1000
モデルの学習は、最大1000回行います。
valid_names=[‘train’, ‘valid’] valid_sets=[lgb_train, lgb_eval]
モデルの検証は、ホールドアウト法で行います。
左側のtrain’sが学習用データセットでの誤差評価、右側のvalid’sが検証用データセットでの誤差評価です。
evaluation_results = {} evals_result=evaluation_results
evaluation_resultsに、学習の経過を保存します。
保存用の箱を用意して、メトリックの履歴を入れていきます。
early_stopping_rounds=20
検証用のデータセットで、モデルの性能が20回改善されないと、学習がストップします。(アーリーストッピング)
verbose_eval=10
学習の経過を10回毎に表示させています。
なお、-1に設定すると、学習経過が非表示になります。
補足
LightGBMには、上記のネイティブな書き方とは別に、scikit-learnに準拠した書き方があります。
model.fit(データセット)のときは、scikit-learnに準拠した書き方なので、注意してください。
モデルの評価
テストデータで予測
# テストデータで予測
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy の計算
accuracy = sum(y_test == y_pred_max) / len(y_test)
print('accuracy:', accuracy)
# feature importanceを表示
importance = pd.DataFrame(model.feature_importance(), index=df_X.columns, columns=['importance'])
display(importance)
予測モデル
テストデータで予測します。
「model.best_iteration」は、アーリーストッピングが適用された361回です。
モデルは、361回目のハイパーパラメータで予測を行います。
多値分類、マルチクラス分類
# 小数点表示
np.set_printoptions(suppress=True)
print(y_pred)
>>
[[0.99939041 0.00030479 0.00030479]
[0.00030479 0.99939041 0.00030479]
[0.33333249 0.33333376 0.33333376]
[0.00030479 0.00030479 0.99939041]
[0.99939041 0.00030479 0.00030479]
以下、省略「y_pred」には、テストデータセットからモデルで予測した値が格納されています。
各列の値は、各クラスに属する0から1までの確率です。
各行の計は1になります。
print(y_pred_max)
>> [0 1 1 2 0 1 2 0 0 1 2 1 1 2 1 2 2 1 1 0 0 2 2 1 0 1 1 2 0 0]「y_pred_max」には、ターゲットのクラスが格納されています。
NumPyのargmax関数を使って、最も確率が高いクラスを予測クラスとしています。
Accuracy(正答率)
テストデータのターゲットクラスと、予測クラスが一致する数を、ターゲットクラスの数で割ることで、Accuracy(正答率)が求められます。
今回のAccuracy(正答率)は、93.3%です。
feature importance(特徴量の重要度)
各特徴量が、どのくらい予測に寄与しているのかを確認できます。
追加したカテゴリー変数も、わずかながら予測に寄与しているようです。
なお、display(importance)は、DataFrame形式の表レイアウトが保持されます。
print(importance)だと、以下のようになります。
importance
sepal length (cm) 5706
sepal width (cm) 2195
petal length (cm) 2136
petal width (cm) 1250
sepal_cat 513
petal_cat 881
LightGBMには、「特徴量の重要度」の計算方法が2つあります。
実は、モデルの構築に役立つのは、パラメータを設定する計算方法です。
詳しくは、次の記事をご覧ください。
【Python覚書】LightGBM「特徴量の重要度」初期値のままではもったいない
学習過程の可視化
# 学習過程の可視化
plt.plot(evaluation_results['train']['multi_logloss'], label='train')
plt.plot(evaluation_results['valid']['multi_logloss'], label='valid')
plt.ylabel('Log loss')
plt.xlabel('Boosting round')
plt.title('Training performance')
plt.legend()
plt.show()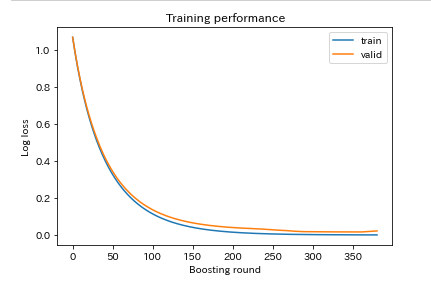
「evaluation_results」に格納しておいた学習過程を可視化します。
学習用と検証用に大きな乖離がないので、過学習はしていないようです。
最も値が良かったのは、361回目のLogLoss 0.0162624ですが、200回くらいで学習をやめてもよさそうです。
まとめ
LightGBMを使った多値分類の手順を紹介しました。
LIghtGBMは、欠損値の処理やカテゴリー変数のダミー変数化など、面倒な前処理を行わなくてもよく、手軽に高い精度のモデルが作成できるので、いろいろ試してみてください。
この記事が学習の参考になれば幸いです。
なお、ホールドアウト法は、取り扱いが簡単ですが、学習に使用できるデータ数が少なくなったり、データの分け方により性能が上下するデメリットがあります。
次は、k分割交差検証を紹介したいと思います。
関連情報
- 機械学習関係の記事
分類 - 【Python覚書】LightGBMで交差検証を実装してみる
- 【Python覚書】XGBoostで多値分類問題を解いてみる
- 【Python覚書】パラメーターチューニング:XGBoostで実装
- 【Python覚書】ディープラーニングで多値分類を解いてみる
- 【Python覚書】アンサンブル学習:XGBoost、LightGBM、CatBoostを組み合わせる(その1)
- 【Python覚書】アンサンブル学習:XGBoost、LightGBM、CatBoostを組み合わせる(その2)
回帰分析 - 【Python覚書】LightGBMで回帰分析を解いてみる
画像処理 - 【Python入門】機械学習の前処理(画像処理のやり方)

