
課題の設定
異なるモデルを組み合わせると、個別に使用するよりも高い予測性能が得られることがあります。
XGBoostには高い予測性能がありますが、LightGBMとCatBoostと組み合わせてみることで、予測性能が向上するのか確かめてみます。
この記事では、次の内容を解説します。
・多数決による予測(Voting)
・スタッキングによる予測(Stacking)
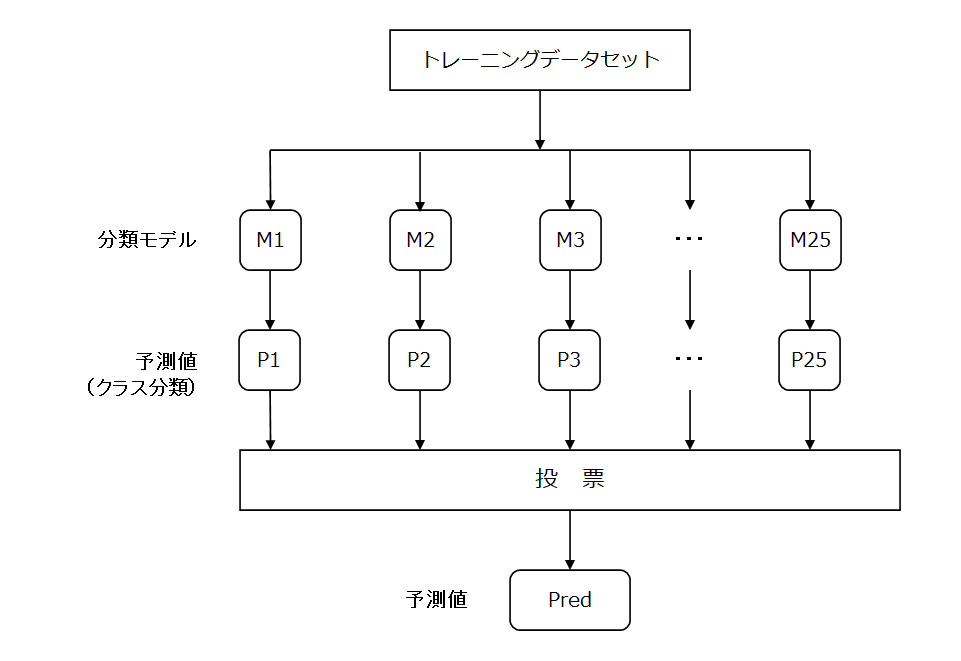
多数決による予測(Voting)とは
多数決による予測とは、各モデルの予測値で「多数決」を行う投票を行い、最も得票の多いクラスを予測値として選択します。
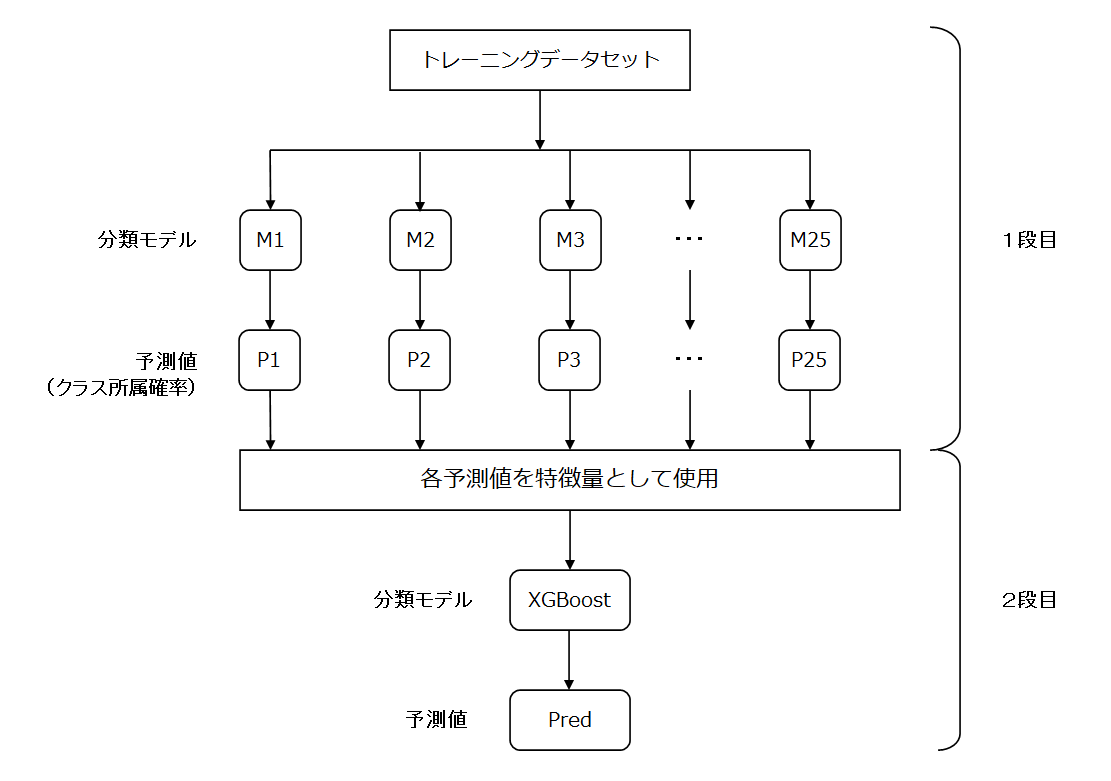
スタッキングによる予測(Stacking)とは
スタッキングによる予測とは、今回の例では、1段目の各モデルから得た予測値を特徴量して、2段目のモデルを学習させて予測値を得るものです。
モデルの組み合わせや積み上げ方は様々ですが、今回は2段のスタッキングを行ってみます。
分析の流れ
データセットの読込からモデルでの予測まで、以下の作業をやってみます。
1段目は、LightGBMについてまとめた以下の記事と同じ流れです。
1段目のコード解説は、こちらをご覧ください(新しいタブで開きます)。
【Python覚書】LightGBMで交差検証を実装してみる
XGBoost、LightGBMのコード解説は、こちらをご覧ください。
【Python覚書】XGBoostで多値分類問題を解いてみる
【Python覚書】LigthGBMで多値分類問題を解いてみる
分析は、scikit-learnのwineデータセットを使用します。
- データセットの読み込み
<1段目: XGBoost、LightGBM、CatBoost> - 特徴量の作成
- パラメータの設定
- モデルの作成
- モデルの評価
<アンサンブル> - 多数決による予測<Voting> ※Votingは1段目まで
- スタッキングによる予測<2段目: XGBoost>
使用するライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import xgboost as xgb
import lightgbm as lgb
from catboost import CatBoost
from catboost import Pool
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn import datasetsXGBoost、LightGBM、CatBoostは、インストールされている前提でインポートしています。
データセット
# wine データセットを読み込む
wine = datasets.load_wine()
X = wine['data']
y = wine['target']
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X = pd.DataFrame(X, columns=wine['feature_names'])sklearn.datasetsからwineデータセットを読み込みます。
説明変数 wine[‘data’]を変数X、目的変数 wine[‘target’]を変数yに格納しています。
さらに、変数Xを、各要素(特徴量)の名称 wine[‘feature_names’]をカラム名として、pandas.DataFrameに格納しています。
特徴量の作成
説明変数を確認します。
先頭の5行を取得します。
df_X.head()
表示が切れていますが、スクロールして確認できます。
なお、上の出力例は画像ですので、スクロールしません。
df_X.info()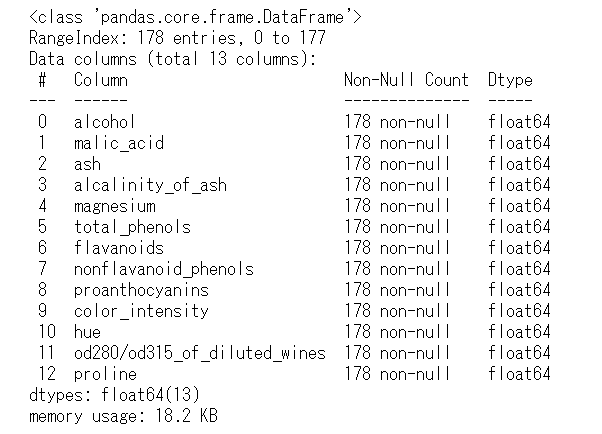
説明変数は、13個で、float64型の数値変数のみです。
その値は、連続する値の数値データで、カテゴリーやラベルを表すものはありません。
今回使用するXGBoost、LightGBM、CatBoostは、トレーニングデータセットの特徴量を標準化する必要はありませんが、その他の手法を使用するときのために、トレーニングデータセットの標準化(平均0、分散1)をしておきます。
# 説明変数を標準化
sc = StandardScaler()
X_std = sc.fit_transform(X)
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X_std = pd.DataFrame(X_std, columns=wine['feature_names'])
df_X_std.head()
学習を難しくするため、13個の説明変数のうち、2個に絞ります。
以下は、XGBoostの学習させたfeature importance(特徴量の重要度)です。
今回は、上から4番目と5番目の特徴量を使用してみます。
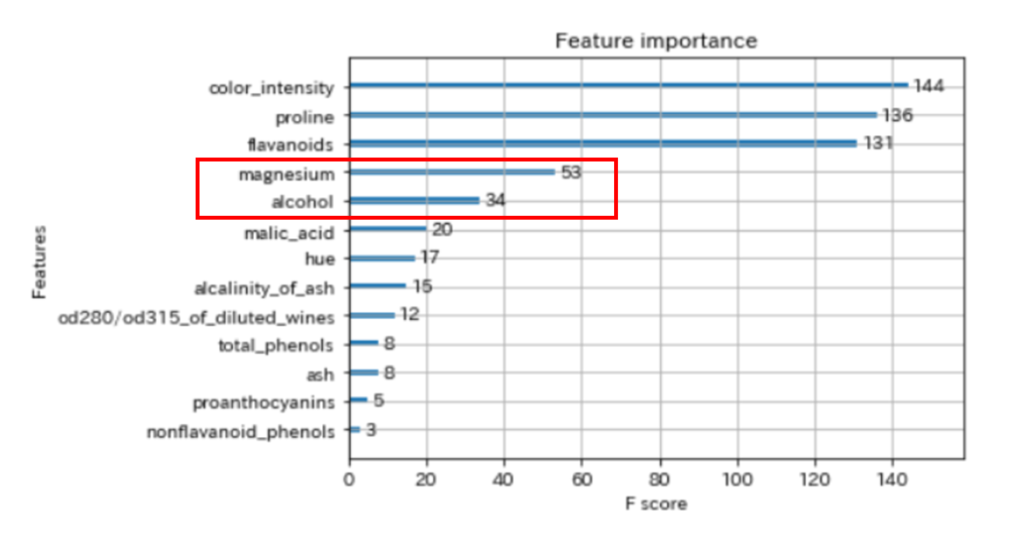
# 説明変数を2個に絞る
# 標準化する前と同じ変数名を再利用しているの、ご注意ください。
df_X = df_X_std[['magnesium', 'alcohol']]同じ名前の変数を再利用するのはよくないですが、横着します。
モデルの作成
XGBoost単独のモデル
モデルの性能比較用に、XGBoost単独のモデルを試してみます。
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y,
test_size=0.2,
random_state=0,
stratify=y)
# 学習データを、学習用と検証用に分ける
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train,
test_size=0.2,
random_state=2,
stratify=y_train)
# データを格納する
# 学習用
xgb_train = xgb.DMatrix(X_train, label=y_train)
# 検証用
xgb_eval = xgb.DMatrix(X_eval, label=y_eval)
# テスト用
xgb_test = xgb.DMatrix(X_test, label=y_test)
# パラメーターの設定
xgb_params = {
'objective': 'multi:softprob', # 多値分類問題
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.1, # 学習率
'eval_metric': 'mlogloss' # 学習用の指標 (Multiclass logloss)
}
# 学習
evals = [(xgb_train, 'train'), (xgb_eval, 'eval')] # 学習に用いる検証用データ
evaluation_results = {} # 学習の経過を保存する箱
bst = xgb.train(xgb_params, # 上記で設定したパラメータ
xgb_train, # 使用するデータセット
num_boost_round=200, # 学習の回数
early_stopping_rounds=10, # アーリーストッピング
evals=evals, # 学習経過で表示する名称
evals_result=evaluation_results, # 上記で設定した検証用データ
verbose_eval=10 # 学習の経過の表示(10回毎)
)
# テストデータで予測
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy の計算
acc = accuracy_score(y_test, y_pred_max)
print('Accuracy:', acc)
df_accuracy = pd.DataFrame({'va_y': y_test,
'y_pred_max': y_pred_max})
print(pd.crosstab(df_accuracy['va_y'], df_accuracy['y_pred_max']))
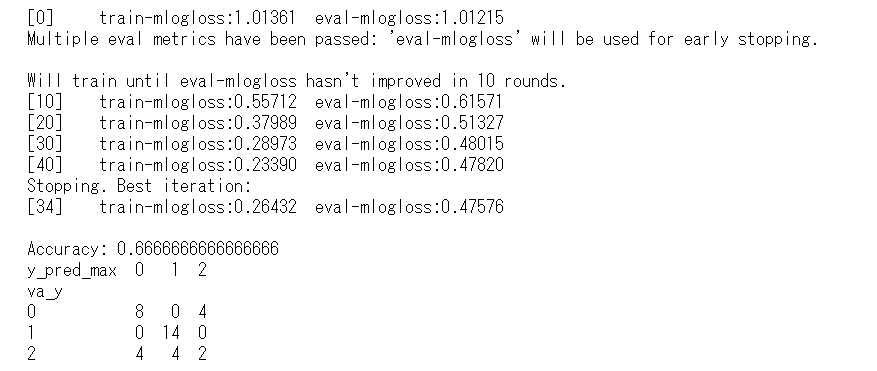
テストデータでのAccuracy(正答率)が66.7%です。
すべての特徴量を使用したAccuracy(正答率)97.2%でしたので、2つの特徴量だけではかなり性能が悪化しています。
多数決による予測(Voting)
いよいよVotingによるアンサンブル学習に取りかかります。
ここでは、XGBoost、LightGBM、CatBoostの分類器を各25個(5つのシード値×5CV)作成するので、75個のモデルで多数決の投票を行います。
それぞれの分類器は、def文のブロックで関数として定義します。
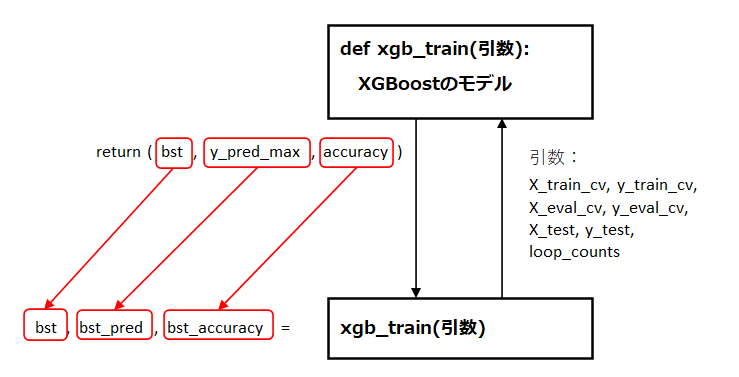
定義した関数を、引数を指定して呼び出すと、戻り値が得られます。
戻り値は、それぞれ変数へ代入します。
XGBoostの関数
def xgb_train(X_train_cv, y_train_cv, X_eval_cv, y_eval_cv, X_test, y_test, loop_counts):
# データを格納する
# 学習用
xgb_train = xgb.DMatrix(X_train_cv, label=y_train_cv)
# 検証用
xgb_eval = xgb.DMatrix(X_eval_cv, label=y_eval_cv)
# テスト用
xgb_test = xgb.DMatrix(X_test, label=y_test)
# パラメータを設定
xgb_params = {
'objective': 'multi:softprob', # 多値分類問題
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.1, # 学習率
'eval_metric': 'mlogloss' # 学習用の指標 (Multiclass logloss)
}
# 学習
evals = [(xgb_train, 'train'), (xgb_eval, 'eval')] # 学習に用いる検証用データ
evaluation_results = {} # 学習の経過を保存する箱
bst = xgb.train(xgb_params, # 上記で設定したパラメータ
xgb_train, # 使用するデータセット
num_boost_round=200, # 学習の回数
early_stopping_rounds=10, # アーリーストッピング
evals=evals, # 学習経過で表示する名称
evals_result=evaluation_results, # 上記で設定した検証用データ
verbose_eval=0 # 学習の経過の表示(非表示)
)
# テストデータで予測
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred_max = np.argmax(y_pred, axis=1)
print('Trial: ' + str(loop_counts))
accuracy = accuracy_score(y_test, y_pred_max)
print('XGBoost Accuracy:', accuracy)
return(bst, y_pred_max, accuracy)LightGBMの関数
def lgbm_train(X_train_cv, y_train_cv, X_eval_cv, y_eval_cv, X_test, y_test):
# データを格納する
# 学習用
lgb_train = lgb.Dataset(X_train_cv, y_train_cv,
free_raw_data=False)
# 検証用
lgb_eval = lgb.Dataset(X_eval_cv, y_eval_cv, reference=lgb_train,
free_raw_data=False)
# パラメータを設定
params = {'task': 'train', # レーニング ⇔ 予測predict
'boosting_type': 'gbdt', # 勾配ブースティング
'objective': 'multiclass', # 目的関数:多値分類、マルチクラス分類
'metric': 'multi_logloss', # 検証用データセットで、分類モデルの性能を測る指標
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.1, # 学習率(初期値0.1)
'num_leaves': 23, # 決定木の複雑度を調整(初期値31)
'min_data_in_leaf': 1, # データの最小数(初期値20)
}
# 学習
evaluation_results = {} # 学習の経過を保存する箱
model = lgb.train(params, # 上記で設定したパラメータ
lgb_train, # 使用するデータセット
num_boost_round=200, # 学習の回数
valid_names=['train', 'valid'], # 学習経過で表示する名称
valid_sets=[lgb_train, lgb_eval], # モデルの検証に使用するデータセット
evals_result=evaluation_results, # 学習の経過を保存
early_stopping_rounds=10, # アーリーストッピングの回数
verbose_eval=0) # 学習の経過を表示する刻み(非表示)
# テストデータで予測
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy の計算
accuracy = sum(y_test == y_pred_max) / len(y_test)
print('LightGBM Accuracy:', accuracy)
return(model, y_pred_max, accuracy)CatBoostの関数
def catboost_train(X_train_cv, y_train_cv, X_eval_cv, y_eval_cv, X_test, y_test):
# データを格納する
# 学習用
CatBoost_train = Pool(X_train_cv, label=y_train_cv)
# 検証用
CatBoost_eval = Pool(X_eval_cv, label=y_eval_cv)
# パラメータを設定
params = {
'loss_function': 'MultiClass', # 多値分類問題
'num_boost_round': 1000, # 学習の回数
'early_stopping_rounds': 10 # アーリーストッピングの回数
}
# 学習
catb = CatBoost(params)
catb.fit(CatBoost_train, eval_set=[CatBoost_eval], verbose=False)
# テストデータで予測
y_pred = catb.predict(X_test, prediction_type='Probability')
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy の計算
accuracy = sum(y_test == y_pred_max) / len(y_test)
print('CatBoost Accuracy:', accuracy)
return(catb, y_pred_max, accuracy)学習の実行
モデルの学習を行います。
大まかな流れは、以下のように2重ループをぐるぐる回します。
5分割のクロスバリデーションを行いますが、この分割のシード値を5回変えます。
性能の推定は、初めに分割したテストデータを使用するホールドアウト法で行います。
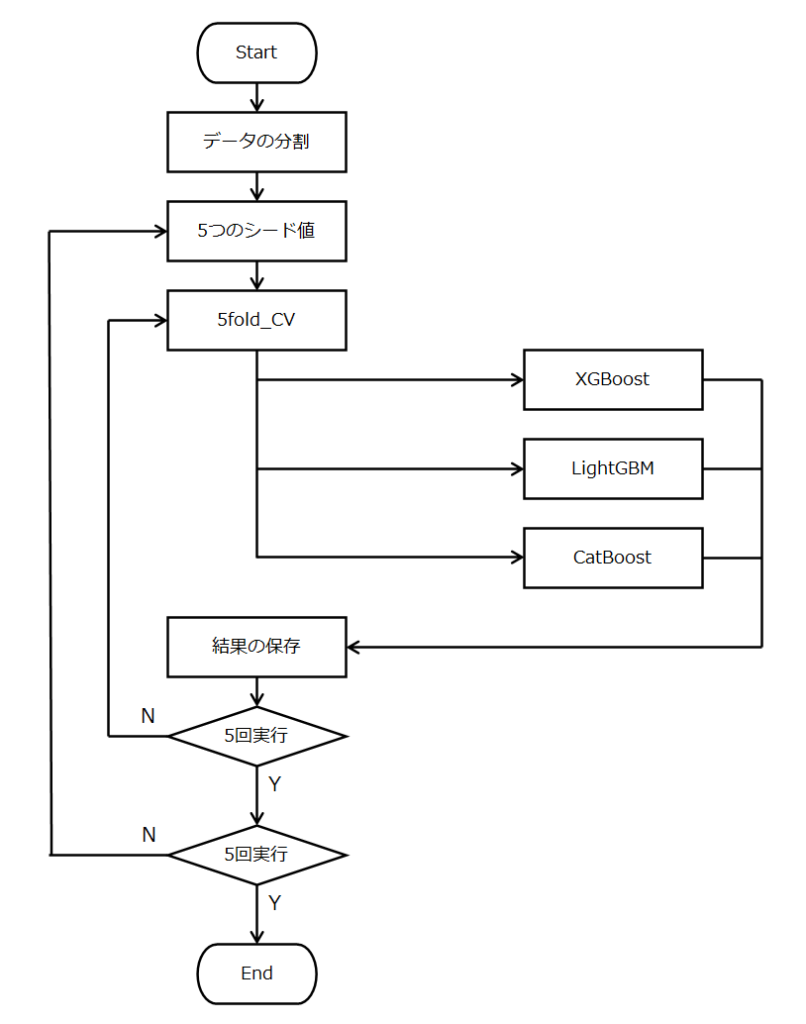
実際のコードは、以下の通りです。
# Voting
# 各5つのモデルを保存するリストの初期化
xgb_models = []
lgbm_models = []
catb_models = []
# 各5つのモデルの正答率を保存するリストの初期化
xgb_accuracies = []
lgbm_accuracies = []
catb_accuracies = []
# 学習のカウンター
loop_counts = 1
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y,
test_size=0.2,
random_state=1,
stratify=y)
# 各5つのモデルの予測を保存する配列の初期化(5seed*5cv*3モデル)
first_preds = np.zeros((len(y_test), 5*5*3))
# 5つのシード値で予測
for seed_no in range(5):
# 学習データの数だけの数列(0行から最終行まで連番)
row_no_list = list(range(len(y_train)))
# KFoldクラスをインスタンス化(これを使って5分割する)
K_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state= seed_no)
# KFoldクラスで分割した回数だけ実行(ここでは5回)
for train_cv_no, eval_cv_no in K_fold.split(row_no_list, y_train):
# ilocで取り出す行を指定
X_train_cv = X_train.iloc[train_cv_no, :]
y_train_cv = pd.Series(y_train).iloc[train_cv_no]
X_eval_cv = X_train.iloc[eval_cv_no, :]
y_eval_cv = pd.Series(y_train).iloc[eval_cv_no]
# XGBoostの学習を実行
bst, bst_pred, bst_accuracy = xgb_train(X_train_cv, y_train_cv,
X_eval_cv, y_eval_cv,
X_test, y_test,
loop_counts)
# LIghtGBMの学習を実行
model, model_pred, model_accuracy = lgbm_train(X_train_cv, y_train_cv,
X_eval_cv, y_eval_cv,
X_test, y_test)
# CatBoostの学習を実行
catb, catb_pred, catb_accuracy = catboost_train(X_train_cv, y_train_cv,
X_eval_cv, y_eval_cv,
X_test, y_test)
# 学習が終わったモデルをリストに入れておく
xgb_models.append(bst)
lgbm_models.append(model)
catb_models.append(catb)
# 学習が終わったモデルの正答率をリストに入れておく
xgb_accuracies.append(bst_accuracy)
lgbm_accuracies.append(model_accuracy)
catb_accuracies.append(catb_accuracy)
# 学習が終わったモデルの予測をリストに入れておく
first_preds[:, loop_counts-1] = bst_pred
first_preds[:, loop_counts-1 + 25] = model_pred
first_preds[:, loop_counts-1 + 50] = catb_pred
# 実行回数のカウント
loop_counts += 1 
モデルの評価
単独のモデルの平均性能
モデルの平均性能を見てみましょう。
25個のモデルについて、正答率(Accuracy)の平均値を算出します。
# 単独のモデルでの、テストデータの正答率
print('XGBoost Accuracy: ', np.array(xgb_accuracies).mean())
print('LightGBM Accuracy: ', np.array(lgbm_accuracies).mean())
print('CatBoost Accuracy: ', np.array(catb_accuracies).mean())XGBoost Accuracy: 0.6855555555555555
LightGBM Accuracy: 0.6355555555555555
CatBoost Accuracy: 0.7288888888888888単独のモデルでは、CatBoostの性能が良いようです。
ただし、留意する点として、単独のモデルは結果に幅が出やすいことです。
先ほどの正答率を箱ひげ図にすると、結果に幅があることがよくわかります。
# 箱ひげ図の作成
plt.figure(figsize=(12, 6))
plt.boxplot(x, whis=3)
plt.xticks(range(1, 4), ['XGBoost', 'LightGBM', 'CatBoost'])
plt.title('Accuracy')
plt.show()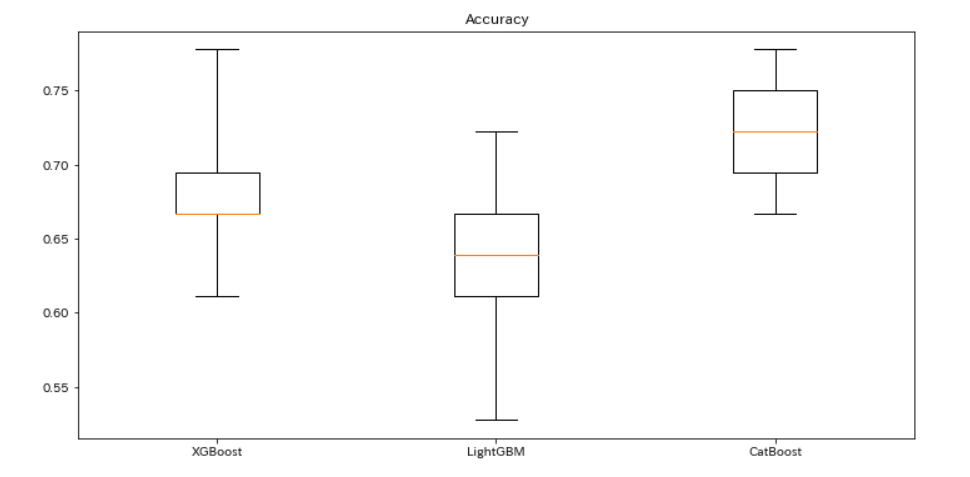
箱ひげ図では、赤い線が中央値を表します。
なお、今回のデータでは、平均値と中央値はほぼ同じです。(計算は省略)
XGBoostでは、最小値61.1%、最大値66.7%と、結果に5.6%の幅があります。
クロスバリデーションを行うことで、モデルの平均性能を推定することが重要だとわかります。
多数決による予測の性能
遂に、多数決による予測です。
保存した単独のモデルの予測を見てみます。
df_first_preds.astype(int).head()
75個のモデルの予測が、各列に保存されています。
これを各行ごとに、0が〇個、1が〇個、2が〇個と集計すると、以下のようになります。
※次のコードは、集計を実行する前では、エラーになります。
first_preds_max.head()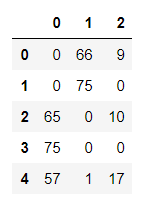
1行目は、1が全会一致の得票数75で予測値となります。
4行目は、票が割れていますが、0が最多の得票数57で予測値となります。
それでは、投票の結果を見てみましょう。
# データ格納用のnumpy行列を作成
first_preds_max = pd.DataFrame(np.zeros((len(y_test), 3)))
# 予測したクラスのデータをpandas.DataFrameに入れる
df_first_preds = pd.DataFrame(first_preds)
# 各列(0,1,2)に、そのクラスを予測したモデルの数を入れる
first_preds_max.iloc[:, 0] = (df_first_preds == 0).sum(axis=1)
first_preds_max.iloc[:, 1] = (df_first_preds == 1).sum(axis=1)
first_preds_max.iloc[:, 2] = (df_first_preds == 2).sum(axis=1)
# 各行で、そのクラスを予測したモデルの数が最も多いクラスを得る
pred_max = np.argmax(np.array(first_preds_max), axis=1)
# Accuracy を計算する
accuracy = sum(y_test == pred_max) / len(y_test)
print('accuracy:', accuracy)
df_accuracy = pd.DataFrame({'va_y': y_test,
'y_pred_max': pred_max})
print(pd.crosstab(df_accuracy['va_y'], df_accuracy['y_pred_max']))
これまでの結果を表にまとめてみます。
| 正答率 | |||||
| XGBoost(単独) | 66.7% | ||||
| seed値 | 5個 | 4個 | 3個 | 2個 | 1個 |
| XGBoost(平均) | 68.6% | 69.2% | 69.1% | 68.9% | 67.8% |
| LightGBM(平均) | 63.6% | 63.2% | 62.4% | 61.4% | 57.8% |
| CatBoost(平均) | 72.9% | 72.6% | 72.4% | 73.1% | 72.8% |
| Voting | 75.0% | 75.0% | 75.0% | 72.2% | 72.2% |
参考に、シード値が1個から4個までの結果も表にまとめています。
正答率を比較すると、seed値が3個以上では、多数決による予測<Voting>が、各モデル単独の予測を上回りました。
モデルがある程度の数になると、性能が安定してくるようです。
今回のケースでは、seed値は3個で十分でした。
計算コストは多くなりますが、とりあえずモデルの性能向上が図れました。
まとめ
XGBoost、LightGBM、CatBoostを組み合わせて、Votingによるアンサンブル学習を行いました。
多数決の原理を利用して、異なるモデルの分類器を組み合わせることで、個別の分類器よりも高い予測性能が期待できることがわかりました。
スタッキング(Stacking)による予測は、(その2)をご覧ください。
補足
学習時に保存したモデルを使用していませんでした。
各モデルは、リストから取り出して使用することができます。
XGBoostのリストには、25個のモデルが保存されてるので、0番目のモデルを使用してみます。
# 保存したモデルで予測
# テストデータ
xgb_test = xgb.DMatrix(X_test, label=y_test)
# 0番目のモデルを取り出し
bst = xgb_models[0]
# 取り出したモデルで予測
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred[:5]array([[0.05185582, 0.83538544, 0.1127588 ],
[0.03909898, 0.8337178 , 0.12718321],
[0.5990458 , 0.04853129, 0.3524229 ],
[0.6565835 , 0.05753071, 0.28588578],
[0.6565835 , 0.05753071, 0.28588578]], dtype=float32)
