
多層のニューラルネットワークを使って、多値分類を解いてみます。
ディープラーニングは、多層のニューラルネットワークを効率よく学習させる仕組みです。
画像や音声の分類とは別の視点で、テーブルデータを分類する強力なツールとして紹介します。
課題の設定
scikit-learnで用意されているwineデータセットを使って、3種類のワインを分類するモデルを作成します。
データセットの読込から学習結果の可視化まで、以下の作業をやってみます。
- データセットの読み込み
- 特徴量の作成
- パラメータの設定
- モデルの作成
- 学習過程の可視化
- 学習結果の可視化
使用するライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
%matplotlib inline
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout
from keras.optimizers import SGD
from keras.optimizers import Adam
from keras.utils import np_utils
from keras.callbacks import EarlyStopping
from sklearn import datasets
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFoldtensorflowとkerasが、インストールされている前提でインポートしています。
インストール方法は、先人のブログがたくさんありますので、自身のPC環境に合った方法を探してみてください。
なお、インポート時にWarningがたくさん出る場合がありますが、無視して大丈夫です。
気になる方は、numpyのバージョンが新しいことが原因だと思いますので、numpy1.16.4を入れた環境を作ってみてください。
「Warning」を非表示にする方法は、次の記事をご覧ください。

データセット
# wine データセットを読み込む
wine = datasets.load_wine()
X = wine['data']
y = wine['target']
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X = pd.DataFrame(X, columns=wine['feature_names'])sklearn.datasetsからwineデータセットを読み込みます。
読み込んだデータは、Bunch型のオブジェクトです。
print(type(wine))
>> <class 'sklearn.utils.Bunch'>Bunch型は、辞書型のサブクラスです。
辞書型と同じように、wine[‘key’]や、wine.keyで、要素を取りだすことができます。
なお、ドット表記の事例が多いようですが、この記事では、要素(特徴量)へのアクセスを明示するために、角括弧([ ])を使用します。
keyの一覧は、辞書のkeys()メソッドで取り出せます。
print(wine.keys())
>> dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])ここでは、説明変数 wine[‘data’]を変数X、目的変数 wine[‘target’]を変数yに格納しています。
変数Xは、各要素(特徴量)の名称 wine[‘feature_names’]をカラム名として、pandas.DataFrameに格納することで、pandasの強力なメソッドが使用できるようにします。
特徴量の作成
説明変数を確認します。
先頭の5行を取得します。
df_X.head()
表示が切れていますが、スクロールして確認できます。
なお、上の出力例は画像ですので、スクロールしません。
データフレームの次元は、shape属性で確認できます。
df_X.shape
>> (178, 13)178行×13列です。
infoメソッドでは、次元の他にも、各カラム名(Dtype)、非欠損値の数(Non-Null Count)、データ型(Dtype)などが確認できます。
df_X.info()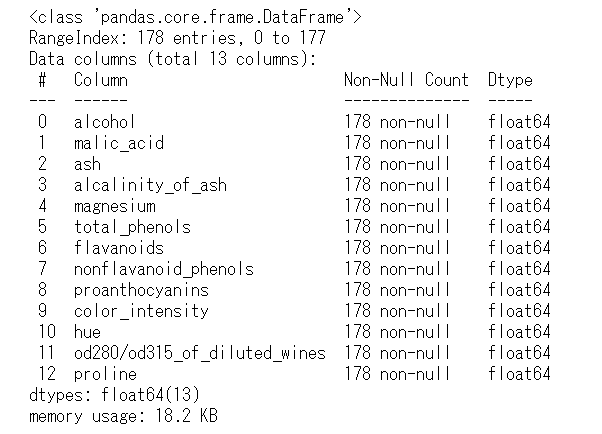
説明変数は、13つで、float64型の数値変数のみです。
その値は、連続する値の数値データで、カテゴリーやラベルを表すものはありません。
説明変数の説明は、以下の公式(英語)をご覧ください。
・scikit-learn(datasets)
説明変数の標準化
モデルの学習が効果的に進むように、説明変数を標準化します。
標準化とは、特徴量の平均値を0、標準偏差を1にすることです。
実際のデータを見てみましょう。
標準化する前のデータをヒストグラムにしてみます。
# 描画サイズ
plt.figure(figsize=(12, 4))
# 左のグラフ
plt.subplot(1, 2, 1)
plt.hist(df_X['alcohol'])
# 右のグラフ
plt.subplot(1, 2, 2)
plt.hist(df_X['magnesium'])
plt.show()
alcoholのデータは11~14.5の範囲にあり、magnesiumのデータは70~162の範囲にあります。
これらのデータを同じように扱うと、値の大きなmagnesiumの方が計算結果に大きな影響を与えることになります。
そこで、各特徴量を同じ重みで扱うために、標準化によってスケーリングを同じにします。
# 説明変数を標準化
sc = preprocessing.StandardScaler()
X_sc = sc.fit_transform(X)
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X_sc = pd.DataFrame(X_sc, columns=wine['feature_names'])
df_X_sc.head()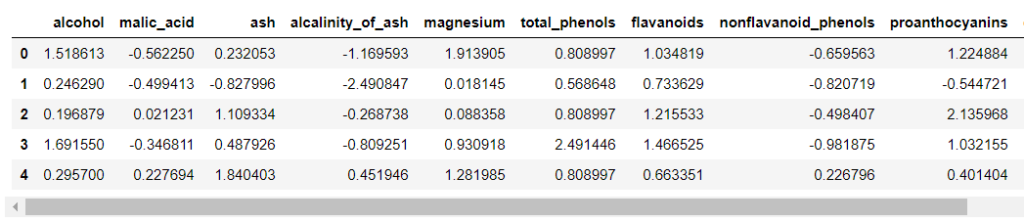
説明変数を標準化しました。
平均値0を中心に、-2から2の間に、全体の95%の値が収まっています。
標準化した後のデータをヒストグラムにしてみます。
# 描画サイズ
plt.figure(figsize=(12, 4))
# 左のグラフ
plt.subplot(1, 2, 1)
plt.hist(df_X_sc['alcohol'])
plt.xlabel('alcohol')
# 右のグラフ
plt.subplot(1, 2, 2)
plt.hist(df_X_sc['magnesium'])
plt.xlabel('magnesium')
plt.show()
標準化により、特徴量(データ)がスケーリングされていることが分かります。
また、標準化した後のヒストグラムの形は、元の形とほぼ同じなので、データの特徴はそのまま残っています。
説明変数を限定
学習を難しくするため、13個の説明変数のうち、2個に絞ります。
# 説明変数を2個に絞る
# 標準化する前と同じ変数名を再利用しているの、ご注意ください。
df_X = df_X_sc[['magnesium', 'alcohol']]
以下は、XGBoostの学習させたfeature importance(特徴量の重要度)です。
今回は、上から4番目と5番目の特徴量を使用してみます。
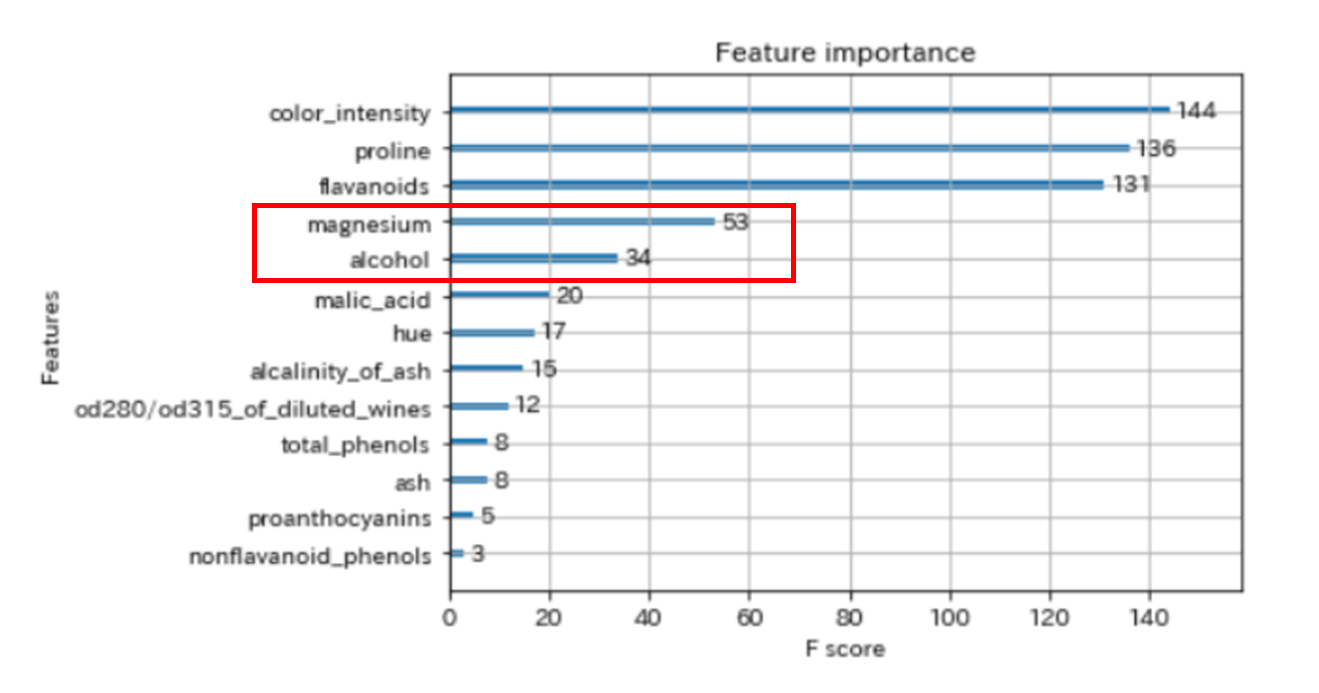
「特徴量の重要度」はXGBoostの記事で解説していますので、こちらをご覧ください。
【Python覚書】XGBoostで多値分類問題を解いてみる
説明変数の視覚化
説明変数を2個に限定したので、データの特徴を散布図(2次元)で確認することができます。
なお、説明変数が4個以上のときは、散布図行列など、2個の説明変数で特徴を確認します。
# 描画サイズ
plt.figure(figsize=(8, 6))
# 説明変数の散布図
colors = ['steelblue', 'green', 'pink']
for i in range(3):
plt.scatter(df_X.iloc[y==i, 0], df_X.iloc[y==i, 1], c=colors[i], edgecolor='white', s=70)
# ラベルとタイトル
plt.xlabel('magnesium')
plt.ylabel('alcohol')
plt.title('目的変数の分布')
# 描画
plt.show()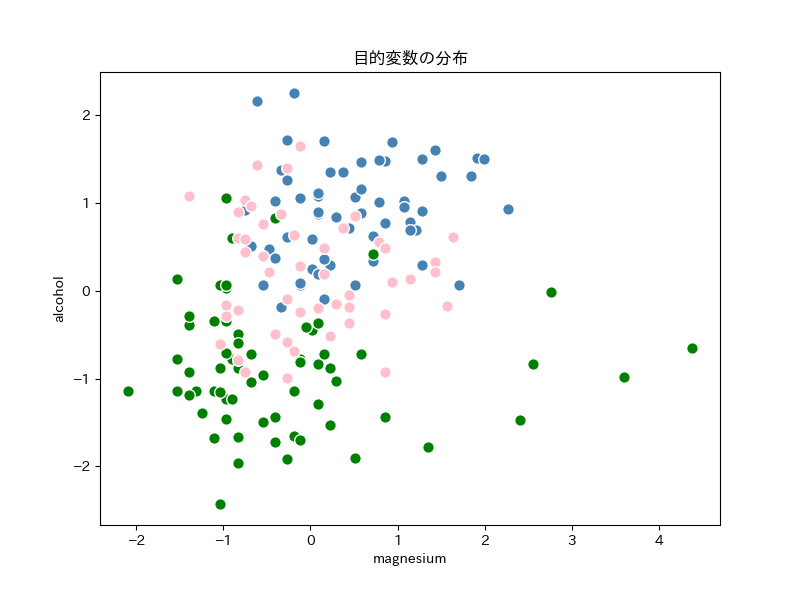
今回の目的は、上の散布図に境界線を引いて、3種類に分類することです。
青とピンクの点は、かなり重なっているので、2個の特徴量で分類することは難しそうです。
分類のイメージを作るために、今回作成するモデルでの分類を見てみます。
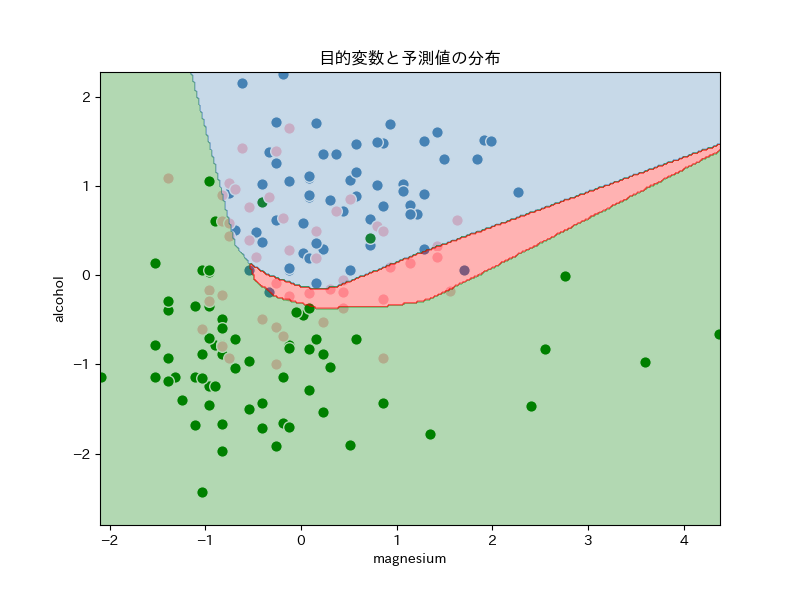
散布図が、3色に塗り分けられています。
今回作成するモデルは、「alcolhol」と「magnesium」の値を使って、エリア内の各点を上図のように予測するようです。
目的変数のカテゴリー化
tensorflow(keras)の目的変数は、正解ラベルの配列を使用します。
kerasのnp_utilsを使用して、目的変数をカテゴリー化します。
# 数値を、位置に変換
# 1次元配列[0,1,2] を、2次元配列 [ [1,0,0],[0,1,0],[0,0,1] ]に変換
y_T = np_utils.to_categorical(y)
scikit-learnを使用して、One-Hotエンコーディングしても同じです。
from sklearn.preprocessing import OneHotEncoder
# OneHotEncoderのインスタンスを生成(sparse=Falseで、2次元のnumpy.ndarray)
OE = OneHotEncoder(sparse=False)
# ラベルを学習して、実行
cat_OneHot = OE.fit_transform(pd.DataFrame(y))詳しくは、XGBoostの記事でOne-Hotエンコーディングをご覧ください。
モデルの作成
モデルの作成を、次のステップで行います。
1. 説明変数(特徴量)と目的変数を、学習用とテスト用に分ける
2. モデルの構築
3. 学習の実行
説明変数(特徴量)と目的変数を、学習用とテスト用に分ける
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y_T,
test_size=0.2,
random_state=0,
stratify=y)
# 学習データを、学習用と検証用に分ける
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train,
test_size=0.2,
random_state=0,
stratify=y_train)ホールドアウト法を使って、データセット全体を3つに分割します。
・学習データ
1. 学習用: モデルの学習に使用
2. 検証用: ハイパーパラメーターの調整に使用
・テストデータ: モデルの評価に使用

モデルの構築
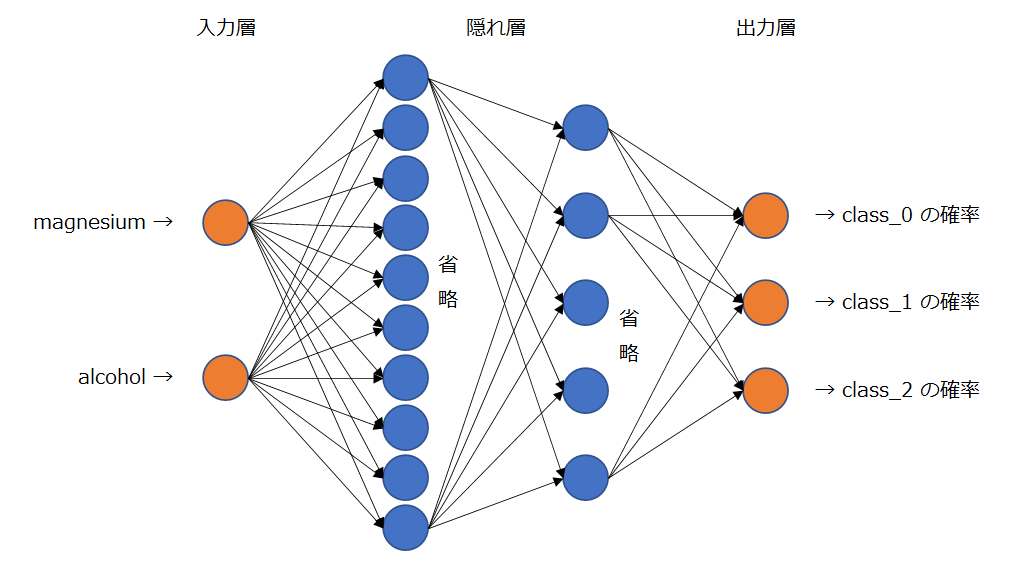
隠れ層が、2層のモデルを構築します。
入力層は、説明変数(特徴量)の個数なので、2個のユニット。
隠れ層の1層目は、10個のユニット。2層目は、5個のユニット。
出力層は、目的変数の個数なので、3個のユニット。
上図で描画を一部省略していますが、各層のユニットが、次層の全ユニットへ結合しています。
隠れ層のユニット数や層数は、説明変数の数や学習に使用できるデータ量により判断します。
今回は、絵に描ける大きさで、精度がでた最小サイズのモデルにしています。
2次元なので、隠れ層は2層で十分だと思います。
通常は、入力層から出力層に向けて、漏斗のように段々と少ないユニットにしていきます。
適切なユニット数は、試行を繰り返して見つけるしかないです。
ただ、後述の「Early-stopping」を使用すれば、大きめモデルを作成し、エポック数を多く設定することで、とりあえず精度のでるモデルが作れると思います。
例えば、各層のユニット数を、50個ずつにしてみると、同程度の精度になります。
いろいろと試行してみてください。
それでは、実際にモデルを構築していきます。
# seed値を固定
np.random.seed(0)
tf.set_random_seed(0)
# モデル構築
model = Sequential()
# 入力層と隠れ層(1層目)
model.add(Dense(units=10, activation='relu', input_dim=2))
# 隠れ層(2層目)
model.add(Dense(units=5, activation='relu',))
# ドロップアウト
層
model.add(Dropout(0.5))
# 出力層
model.add(Dense(units=3, activation='softmax'))
# モデルの概要を出力
model.summary()
seed値を固定しているのは、モデルの再現ができるようにするためです。
モデルの構成は、上図のとおりで、出力層の前にドロップアウト層を加えています。
とりあえずは、モデルの正解率や汎化能力が上がる「おまじない」と思っておけば大丈夫です。
隠れ層の活性化関数は、ディープラーニングでよく使用される「ReLU関数」にしています。
Kerasの公式サイトで、使用可能な活性化関数が確認できます。
これも、定番を選んでおけばよいです。
出力層は、「softmax関数」で、各クラスに所属する確率を出力します。
各クラスになる確率は、合計すると「1」になります。
モデルの構築ができたので、次は、モデルをコンパイルします。
# モデルのコンパイル
model.compile(
loss='categorical_crossentropy', # 多値分類
optimizer=Adam(lr=0.01), # オプティマイザ(Adam最適化)
metrics=['categorical_accuracy']) # 評価関数損失関数は、多値分類なので「categorical_crossentropy」を使用します。
Kerasの公式サイトで、利用可能な損失関数が確認できます。
最適化アルゴリズム(オプティマイザ)は、「Adam最適化」を使用します。
一般的に、学習の収束が早いと言われています。
Kerasの公式サイトで、利用可能なオプティマイザが確認できます。
評価関数は、「categorical_accuracy」を使用します。
評価関数の結果は、訓練に使用されることはありませんが、モデルの性能を測り、訓練の経過を可視化するために取得しておきます。
Kerasの公式サイトで、利用可能な評価関数が確認できます。
モデルの学習
# Early-stopping
early_stopping = EarlyStopping(patience=10, verbose=0)
# モデルの学習
history = model.fit(X_train, y_train, # トレーニングデータ
epochs=500, # トレーニングの回数
batch_size=30, # 勾配更新ごとのサンプル数
verbose=1, # 進行状況の表示(0:非表示、1,2:表示)
validation_data=(X_eval, y_eval), # 評価用データ
callbacks=[early_stopping]) # アーリーストッピング
モデルの学習(訓練)を行います。
まず、コールバック関数の「Early-stopping」を設定しています。
損失関数の改善が、「patience」で指定したエポック数の間にないと、訓練を終了します。
Kerasの公式サイトで、コールバック関数の使い方が確認できます。
アーリーストッピングを使用することで、モデルの過学習を抑制することができます。
fitメソッドを使用して、「epochs」で設定した回数の試行で、モデルを学習させます。
各試行の最後に、損失と評価関数に使用するデータは、「validation_data」で設定します。
Kerasの公式サイトで、fitメソッドの使い方が確認できます。
「compile」や「fit」は、Modelクラスのメソッドです。
今回使用していない引数(パラメーター)がたくさんありますので、公式サイトを是非ご覧ください。
モデルの評価
モデルの性能
モデルの学習が終わりましたので、結果を見てみましょう。
# テストデータで予測
y_pred = model.predict(X_test)
y_pred_max = np.argmax(y_pred, axis=1)
# to_categorical の逆変換
_, y_test_acc = np.where(y_test > 0)
# 正答率
accuracy = accuracy_score(y_test_acc, y_pred_max)
print('Neural Network:', accuracy)Neural Network: 0.7222222222222222テストデータで、72.2%の正答率です。
分類の難度が高いので、よい結果が得られていると思います。
モデルの予測結果「y_pred」は、3クラスのいずれかに属する確率です。
次行の「np.argmax()」で、いちばん確率が高いクラスを選択しています。
また、正答はカテゴリーの配列に変換しているので、元の値に戻しています。
正答率は、scikit-learnのaccuracy_scoreメソッドに、引数の正答と予測値を与えて計算しています。
学習経過の可視化」
次に、「history」に出力している学習経過を、「vars()関数」を使って見てみます。
vars(history)
上図は、画像なのでスクロールできませんが、実際にはエポックごとの値が出力されています。
辞書型で保存されているので、history.history[‘loss’]のように指定して、値を取り出します。
ちなみに、オブジェクト名「hisitory」キー「history」キー「loss」です。
オブジェクト名と、キーが同じ「history」で紛らわしくなっています。
それでは、損失関数の経過を可視化してみます。
# 描画サイズ
plt.figure(figsize=(8, 5))
# 学習過程の可視化
plt.plot(history.epoch, history.history['loss'], label='train')
plt.plot(history.epoch, history.history['val_loss'], label='valid')
plt.xticks(range(0, len(history.epoch)+1, 50))
plt.ylabel('loss')
plt.xlabel('epochs')
plt.title('Training performance')
plt.legend(loc='upper right')
plt.show()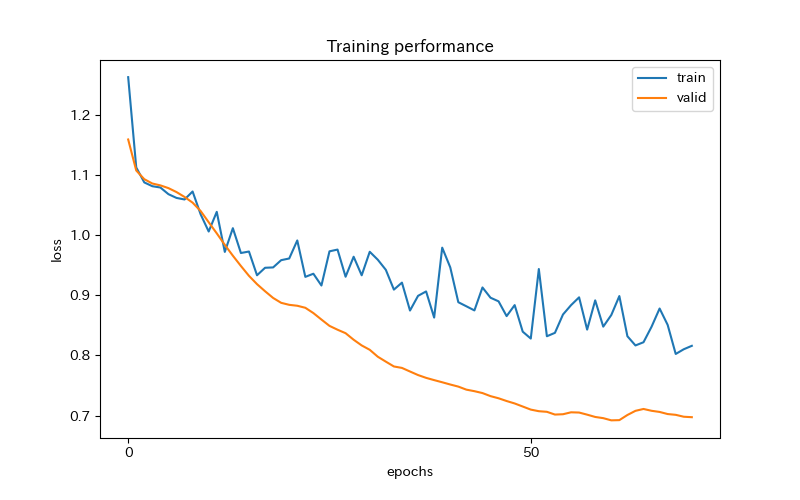
学習は、アーリーストッピングにより70回で止まっています。
学習用データの値の方がよくない結果となっており、検証用データのlossは、きれいに減少しています。
次に、正答率の経過を可視化してみます。
# 描画サイズ
plt.figure(figsize=(8, 5))
# 学習過程の可視化
plt.plot(history.epoch, history.history['categorical_accuracy'], label='train')
plt.plot(history.epoch, history.history['val_categorical_accuracy'], label='valid')
plt.xticks(range(0, len(history.epoch)+1, 50))
plt.ylabel('Accuracy')
plt.xlabel('epochs')
plt.title('Training performance')
plt.legend(loc='lower right')
plt.show()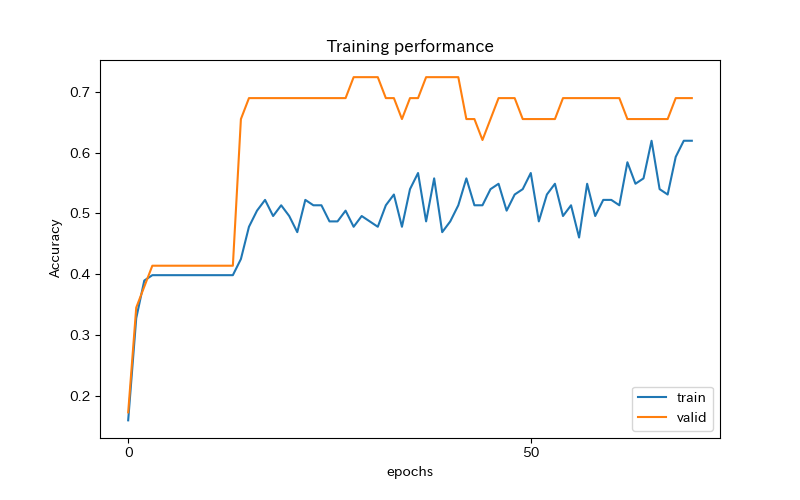
検証用データの正答率は、早い段階で70%台に到達しています。
なお、評価関数の結果は、学習やアーリーストッピングに使用していません。
学習結果の可視化
最後に、モデルの予測を見てみましょう。
# 描画サイズ
plt.figure(figsize=(8, 6))
# 説明変数の散布図
colors = ['steelblue', 'green', 'pink']
for i in range(3):
plt.scatter(df_X.iloc[y==i, 0], df_X.iloc[y==i, 1], c=colors[i], edgecolor='white', s=70)
# グリッドポイントの生成
x_min = df_X['magnesium'].min().round(1)
x_max = df_X['magnesium'].max().round(1)
y_min = df_X['alcohol'].min().round(1)-0.4
y_max = df_X['alcohol'].max().round(1)
gp_x, gp_y = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 各グリッドポイントで予測
Z = model.predict_classes(np.array([gp_x.ravel(), gp_y.ravel()]).T)
Z = Z.reshape(gp_x.shape)
# グリッドポイントの等高線のプロット
cmap = ListedColormap(['steelblue', 'green', 'red'])
plt.contourf(gp_x, gp_y, Z, alpha=0.3, cmap=cmap)
# ラベルとタイトル
plt.xlabel('magnesium')
plt.ylabel('alcohol')
plt.title('目的変数と予測値の分布')
# 描画
plt.show()散布図のエリア内に、0.02刻みの格子を作り、その各点でのモデルの予測値で色塗りをしています。
「青」と「緑」は、きれいに分類できているように見えます。
しかし、「青」や「緑」に塗りつぶされたエリアに、「ピンク」の点が多くみられます。
重なり合った部分の「ピンク」はあきらめて、中央のせまいエリアのみ「ピンク」に分類しています。
「alcolhol」と「magnesium」の値だけでは、これ以上の精度向上は難しいと思います。
別の特徴量を加えることで、精度の向上を試みてください。
まとめ
多層のニューラルネットワークを使って、多値分類を解いてみました。
ニューラルネットワークは、モデルの構築に自由度が高い分、LightGBMやXGBoostよりも、敷居が高い印象を持っています。
今回の実装は、シンプルな構造なので、隠れ層の「層数」や「ユニット数」、使用する特徴量を変えてみると、面白いと思います。
Kerasは、数式なしでニューラルネットワークを使えるライブラリです。
手を動かして、試してみてください。

