データ分析の分野でPythonを学習するとき、実際のデータを分析してみると足りない力がよくわかります。
機械学習の入門書では、分類や回帰の手法解説が中心になり、データ加工や可視化によって「きれいなデータ」にしていく段階がはぶかれています。
実際の業務では、統計的な手法で、データをまとめたり、可視化することは重要なスキルとなります。
データ加工の実践として、無償で公的統計データは手に入れられるので、これを分析してみます。
生データから一定の加工がされたデータですが、用途に応じて再加工する必要があり、一連の前処理にちょうどよい素材だと思います。
分析の目的(今回の課題)
- 政令指定都市が、どのような分野に予算を使っているか分析する
- 特定の都市を深掘りして分析してみる
分析対象の統計表
政府統計のポータルサイトは、「e-Stat 政府統計の総合窓口」です。
今回は、政府統計名「地方財政状況調査」の表番号14「性質別経費の状況」を使用します。
調査年月「2019年」のページは、こちらです。
<リンクをクリックすると、新しいタブが開きます。>

統計表
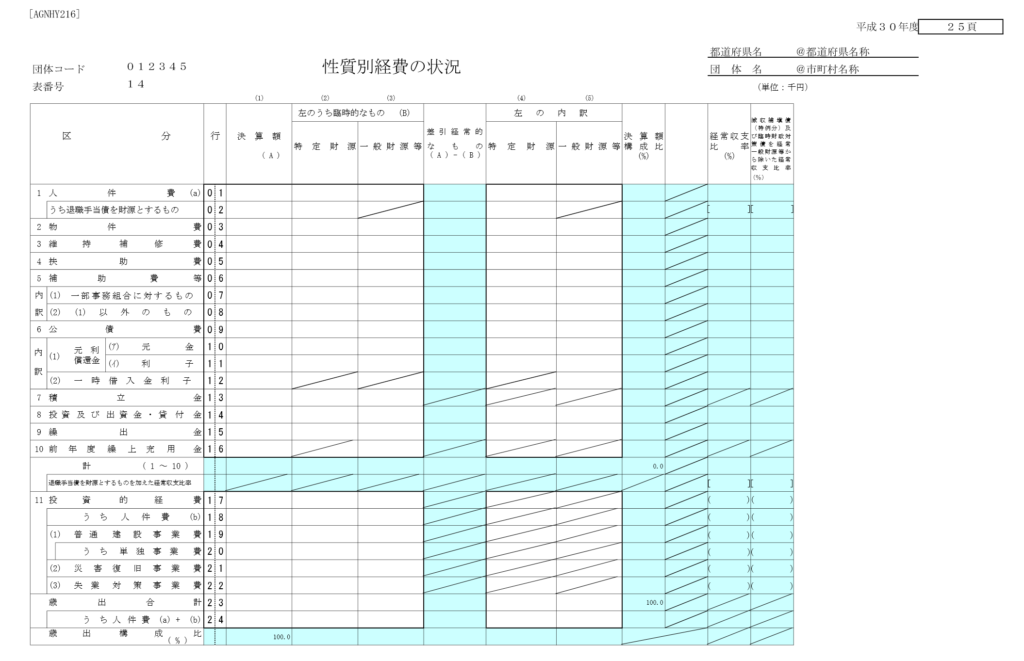
使用する統計表は、以下のようにクロス集計されています。
縦軸の「区分」で性質別に集計されており、横軸が経費の内訳になっています。
今回は「決算額」を使用すれば良さそうです。
分析の実践
今回のタスクは、統計的な手法になります。
一定のルールに基づいて集められたデータを分析し、新たな知見を得ることが目的になります。
一連の作業は以下のようになります。
- データの入手
- データの加工(前処理)
- データの整形(前処理)
- データの可視化
- 分析の考察
では、さっそく作業に取りかかりましょう。
データの入手
分析に使用するデータは、政府統計のポータルサイトから入手します。
分析には、オープンソースの分析用ツール「Jupyter Notebook」を使用します。
まずは、使用するライブラリをインポートします。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
データ は「 地方財政状況調査 」のページからCSVファイルをダウンロードすることができます。今回は、直接URLを指定して読み込みます。
注意点は、公開されているCSVファイルがWindows用の文字コードで作成されているため、引数で指定する必要があります。
# データのURL
file_html_1 = 'https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031885633&fileKind=1'
file_html_2 = 'https://www.e-stat.go.jp/stat-search/file-download?statInfId=000031885634&fileKind=1'
# Windows用の文字コードで、ファイルを読み込み
df_14_1 = pd.read_csv(file_html_1, encoding='cp932')
df_14_2 = pd.read_csv(file_html_2, encoding='cp932')2つのCSVファイルで公開されてデータを読み込むことができました。
分析に使用できるように、データを加工していきます。
データの加工(前処理)
まず、データがきちんと読み込めているか、最初の3行を確認します。
df_14_1.head(3)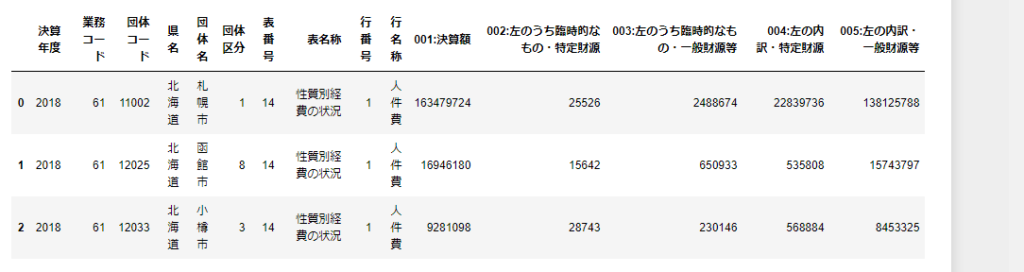
大丈夫そうなので、データのサイズを確認します。
print(df_14_1.shape)
print(df_14_2.shape)(63079, 15)
(12615, 15)データの結合
2つのファイルに分割されているデータを縦に結合します。
df_14 = pd.concat([df_14_1, df_14_2], axis=0)
print(df_14.shape)(75694, 15)文字列から整数へ変換
列名「001:決算額」のデータ型を確認します。
df_14['001:決算額'].dtypedtype('O')object型(文字列)なので、整数に変換する必要があります。
object型(文字列)のままで、0行目と1行目を加算すると、文字列が連結されます。
line_0 = df_14.iloc[0]['001:決算額']
line_1 = df_14.iloc[1]['001:決算額']
print(line_0 + line_1)'16347972416946180'
整数へは、astype(np.int64)で変換できます。
df_14['001:決算額'].astype(np.int64)ここでは、残念ながらエラーが返ってきます。
列名「001:決算額」 に、数字以外のデータが含まれていないか確認します。
df_14[~df_14['001:決算額'].str.isdecimal()]str.isdecimal()は、df_14[‘001:決算額’]の各行が数字のみならTrueを返します。
文頭のチルダ「~」で、「それ以外」となり、数字のみではない行を抽出します。
複数のヘッダーと同じ内容の行が抽出されるので、最初に該当する行の前後を確認します。
df_14.iloc[3152:3155]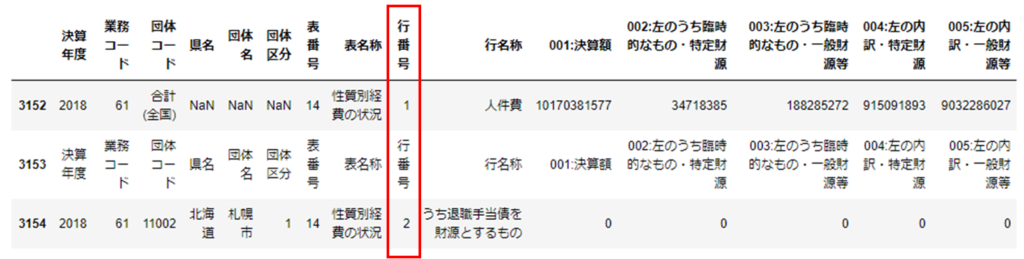
列名「行番号」の値が1,2,3と変わるごとにヘッダーがあるようです。
集計には必要ないので、行中のヘッダー行を削除します。
header_index = df_14.query('行番号 == "行番号"').index
df_14.drop(header_index, inplace=True)列名「行番号」が、値「行番号」となっている行名(index)を指定し、削除しました。
df_14.drop()は、コピーを返すので、引数(inplace=True)を設定して、元データを更新します。
改めて、列名「001:決算額」を整数に変換します。
df_14['001:決算額'] = df_14['001:決算額'].astype(np.int64)
df_14['001:決算額'].dtypedtype('int64')列名「001:決算額」 は、整数に変換できました。
今回は使用しませんが、 列名「001:決算額」から右の列をまとめて整数にすることもできます。
astype(辞書型)で、辞書型に「変換する列」と「データ型」を指定します。
以下は、辞書内包表記でのサンプルコードです。
# 辞書型で、「変換する列」と「データ型」を指定
dict_dtype = {i: np.int64 for i in df_14.columns[10:]}
df_14 = df_14.astype(dict_dtype)
次は、列名を変更します。
列名の変更
このデータは、列名にトラップがあったので、列名を変更します。
まずは、列名を確認します。
df_14.columnsIndex(['決算年度', '業務コード', '団体コード ', '県名', '団体名', '団体区分', '表番号', '表名称', '行番号',
'行名称', '001:決算額', '002:左のうち臨時的なもの・特定財源', '003:左のうち臨時的なもの・一般財源等',
'004:左の内訳・特定財源', '005:左の内訳・一般財源等'],
dtype='object')列名「’団体コード ‘」は文末に、半角スペースが付いています。
どこかでミスがあったのか、なぞのネーミングです。
半角スペースを含む列名では、query関数を使用した抽出ができないので、列名を変更します。
df_14.rename(columns={'団体コード ': '団体コード'}, inplace=True)半角スペースが付いていない列名「団体コード」に変更しました。
df_14.rename()は、コピーを返すので、引数(inplace=True)を設定して、元データを更新します。
データの整形(前処理)
データフレーム「df_14」には、政令指定都市以外の都市や、分析の対象ではない行や列があります。
分析に必要なデータのみになるよう、以下の整形します。
- 「団体区分」を使用して、政令指定都市を抽出する
- ピボットテーブルで、各政令指定都市が1行になるようにする
- ピボットテーブルで作成した表の列を、分析に必要な列だけに絞り込む
- ピボットテーブルで作成した表を、構成割合にする
「団体区分」を使用して、政令指定都市を抽出する
まず、query関数で政令指定都市を抽出します。
団体区分「1」が、政令指定都市です。
文字列の「1」なので、ダブルコーテーションで囲みます。
df_14_政令市 = df_14.query('団体区分 == "1"')ピボットテーブルで、各政令指定都市が1行になるようにする
ピボットテーブルで、各政令指定都市が1行になるようにします。
エクセルと同じように使用し、indexが縦軸、columnsが横軸、valuesが集計対象です。
aggfuncが集計方法で、np.sumは合計値です。
df_14_政令市_pivot = pd.pivot_table(df_14_政令市, index=['団体コード', '団体名'], columns='行名称',
values='001:決算額', aggfunc=np.sum)ピボットテーブルで作成した表の列を、分析に必要な列だけに絞り込む
ピボットテーブルで作成した表の列を、分析に必要な列だけに絞り込みます。
# 列の指定
list_columns = ['人件費', '物件費', '維持補修費', '扶助費', '補助費等', '公債費', '積立金',
'投資及び出資金・貸付金', '繰出金', '前年度繰上充用金', '投資的経費', '歳出合計']
# 列の絞り込み
df_14_政令市_pivot = df_14_政令市_pivot[list_columns]
整形したデータを確認します。
df_14_政令市_pivot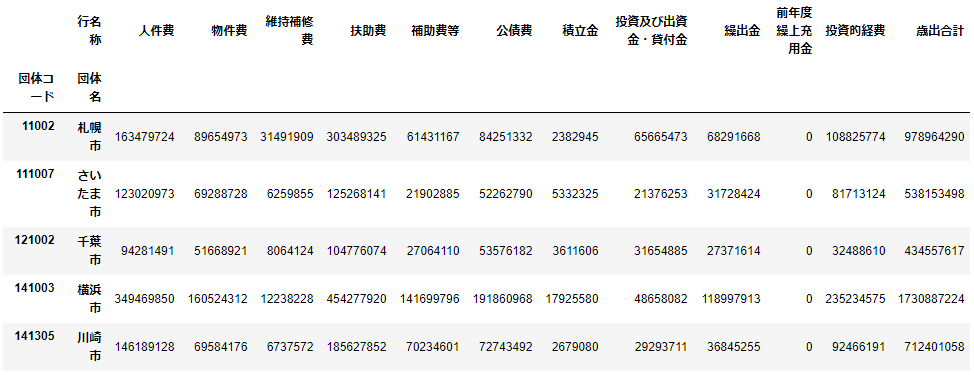
政令指定都市の決算額を、性質別にまとめることできました。
念のため、0行目の横計が歳出合計と一致しているか、確認します。
print(df_14_政令市_pivot.iloc[0][list_columns][:11].sum())
print(df_14_政令市_pivot.iloc[0][list_columns][11])978964290
978964290横計と歳出合計は一致しており、0行目の出力値とも一致しています。
表全体でも、確認します。
0行目を指定したiloc[0]を、すべての行iloc[:]に変更しています。
print(df_14_政令市_pivot.iloc[:][list_columns].sum()[:11].sum())
print(df_14_政令市_pivot.iloc[:][list_columns].sum()[11].sum())13824379124
13824379124表全体でも、正しく集計できているようです。
ここまでで、各政令指定都市の性質別決算額を表にまとめることできました。
ピボットテーブルで作成した表を、構成割合にする
最後に、性質別の決算額を歳出合計で割って、構成割合にします。
これで、歳出規模が異なっている団体間の比較ができるようになります。
作成したピボットテーブルのコピーし、歳出合計で各要素を割ります。
# ピボットテーブルのコピー
df_14_政令市_pivot_ratio = df_14_政令市_pivot.copy()
# 各行の要素を、その行の歳出合計で割る
for i in range(len(df_14_政令市_pivot_ratio)):
df_14_政令市_pivot_ratio.iloc[i] = (df_14_政令市_pivot_ratio.iloc[i] /
df_14_政令市_pivot_ratio.iloc[i]['歳出合計'] *100)
# indexを振りなおす
df_14_政令市_pivot_ratio.reset_index(inplace=True)
# 表の表示
df_14_政令市_pivot_ratio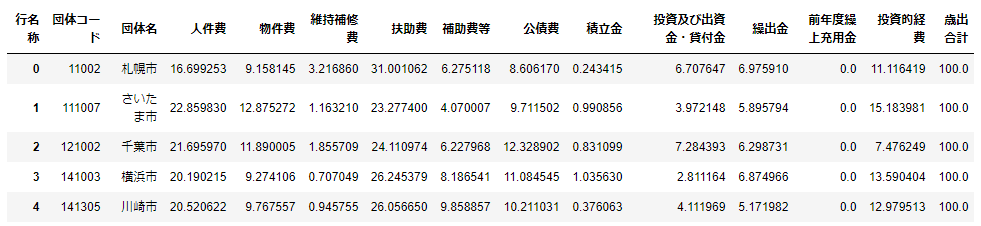
分析の目的は、「政令指定都市が、どのような分野に予算を使っているか分析する」です。
今回、作成したデータを使って、分析の目的は説明できそうです。
より直感的な理解ができるように、データの可視化を行います。
データの可視化
箱ひげ図を使って、可視化します。
箱ひげ図は、データのばらつきが分かりやすく表現されます。
# 性質別に集計
x = np.array([])
for i in list_columns[:11]:
tmp = df_14_政令市_pivot_ratio[i].values
x = np.append(x, tmp)
x = x.reshape(11, 20)
x = tuple(x)# 箱ひげ図の作成
plt.figure(figsize=(15, 8))
plt.boxplot(x, whis="range")
plt.xticks(range(1,12), list_columns[:11])
plt.title('政令指定都市 性質別構成比') # 日本語フォントの設定が必要です
plt.show()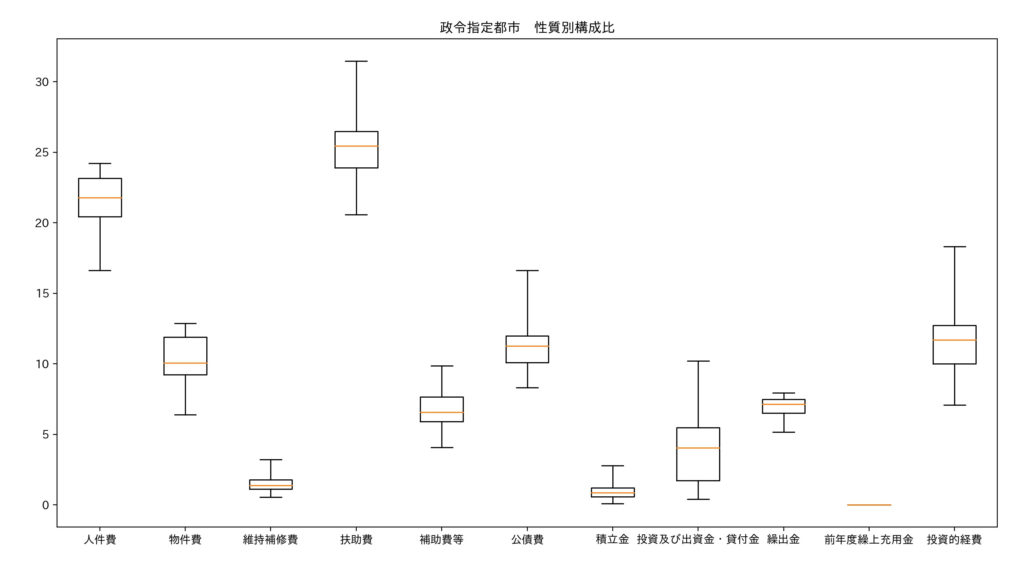
箱ひげ図の見方は、以下のとおりです。
・ひげの上端が最大値、下端が最大値
・箱の上端が第3四分位数、下端が第1四分位数
・箱の中にある赤線が中央値
上の箱ひげ図から、政令指定都市の決算額は、扶助費が最も多く、次に人件費となります。
分析の考察
政令指定都市の決算額を、箱ひげ図(性質別の構成比)で可視化しました。
この図から、次のようなことが読み取れます。
・決算額は、扶助費、人件費、公債費の順で多い
・決算額の上位は、義務的経費(扶助費、人件費、公債費 )
・投資的経費に対して、維持補修費が少ない
・団体によるばらつきが結構大きい
(扶助費だと、最大と最小の団体で差が10ポイントもある)
このような点から、次の分析へと深掘りしていくと良いと思います。
参考に、決算額の割合が一番大きい扶助費を見てみましょう。
df_14_政令市_pivot_ratio[['団体コード', '団体名', '扶助費']].sort_values('扶助費')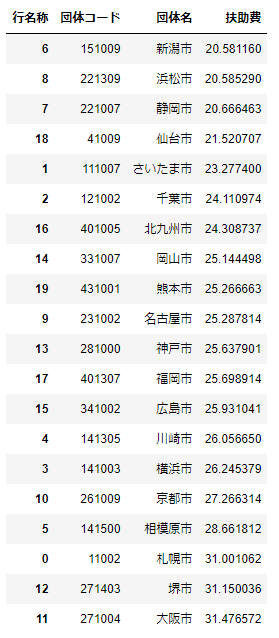
扶助費が最も大きいのは、大阪市の31%で、最も小さいのが、新潟市の21%です。
大阪市は、社会保障が充実しているのでしょうか。
扶助費の内訳は、別のデータを分析しないとわかりません。
ここでは、大阪市と新潟市の値を、箱ひげ図にプロットしてみます。
# 大阪市と新潟市のデータを集計
df_大阪市 = df_14_政令市_pivot_ratio.query('団体コード == "271004"')[list_columns].values
df_新潟市 = df_14_政令市_pivot_ratio.query('団体コード == "151009"')[list_columns].values
# 箱ひげ図の作成
plt.figure(figsize=(15, 8))
plt.boxplot(x, whis="range")
plt.scatter(range(1,12), df_大阪市.reshape(-1)[:11], color='r', label='大阪市')
plt.scatter(range(1,12), df_新潟市.reshape(-1)[:11], color='b', label='新潟市')
plt.xticks(range(1,12), list_columns[:11])
plt.title('政令指定都市 性質別構成比')
plt.legend(loc='upper right')
plt.show()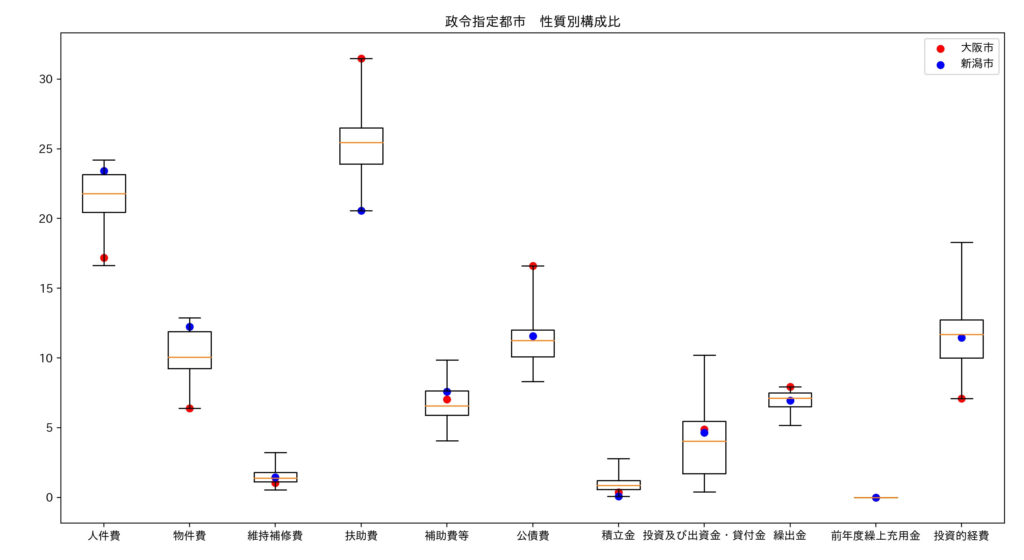
箱ひげ図に、大阪市と新潟市のデータを散布図としてプロットしました。
赤点が大阪市、青点が新潟市のデータです。
大阪市は、扶助費や公債費の割合が大きく、人件費、物件費、投資的経費の割合が小さいです。
他都市よりも公債費の割合が大きいのに、投資的経費が小さいため、過去に行った投資の負担が大きく、将来への投資ができていない印象です。
新潟市は、扶助費の割合が小さく、人件費や物件の割合が大きいです。
公的扶助の割合が小さいため、市民が医療や福祉に頼らず、就労による生活をしている印象です。
逆に考えると、医療機関や福祉施設が十分に整備されていないため、社会保障費の支出が少ないのかもしれません。
これで、2つ目の目標「特定の都市を深掘りして分析してみる」も達成できました。
各都市の個別状況は、別のデータを分析して性質の内訳を見ていく必要がありますが、政令指定都市がどのような分野に予算を使っているかは把握できたと思います。
まとめ
政府統計のデータ分析することで、実践的なデータハンドリングを試みてみました。
一定の加工がされている「きれいなデータ」ですが、分析に使用するまでには、複数の工程を経る必要がありました。
さまざまな関数の知識や、for文などのアルゴリズムなど、プログラミングの技術も必要です。
データ分析の分野で注目されている機械学習では、今回のような前処理を行った大量のデータを使用して、分類や数値予測を行います。
今回の「性質別の決算額」を使って、「市民の平均寿命」や「一人当たりの税収」などを予測するモデルを作ることもできますよ。
長い記事になりましたが、ここまでお付き合いいただきありがとうございます。
関連情報
記事で使用した関数やアルゴリズムを解説しています。
こちらもご覧ください。