
Pandasで出力を見やすく整形
scikit-learnのグリッドサーチやランダムサーチを使って、XGBoostのハイパーパラメータをチューニングする方法を、以下の記事にまとめました。
【Python覚書】パラメーターチューニング:XGBoostで実装
その中で、Pandasを使って、学習の出力を整えています。
記事の本筋からはずれるので割愛した解説を、この記事で行いたいと思います。
コードの解説
パラメーターの学習
この記事で使用するデータを作成しているコードです。(元記事の該当箇所)
bst_rs = bst_rs.fit(X_train,
y_train,
early_stopping_rounds=10,
eval_set=[(X_eval, y_eval)],
eval_metric='mlogloss',
verbose=0)bst_rsの学習を行い、その結果を同じbst_rsへ入れています。
<補足>
上記の記事を、手元で動かしてみていただきたいと思いますが、この記事からご覧の方は、以下のファイルをダウンロード後、Jupyter Notebookの作業をしているディレクトリ(カレントディレクトリ)に解凍してご使用ください。
カレントディレクトリは、次のコマンドで確認できます。
# カレントディレクトリ名の取得
%pwdzipファイルの中身は、「bst_rs.pkl」です。
保存したファイルの読み込みは、Pandas.read_pickle()関数を使用します。
import numpy as np
import pandas as pd
import xgboost as xgb
# ファイルの読み込み
bst_rs = pd.read_pickle("bst_rs.pkl")
bst_rs
Pandas.read_pickle()関数の解説は、以下の記事をご覧ください。
【Python入門】pickleファイルへ保存し、読み込む方法
インスタンスの中身
vars(オブジェクト)で、オブジェクトの中身(辞書:dict型)を見ることができます。
公式サイト: vars([object])
更に、辞書の値からキーを抽出すると、下記のようになります。
vars(bst_rs).keys()
交差検証の結果は、赤で囲った「cv_results_」に入っています。
交差検証の結果
「cv_results_」のキーを抽出すると、交差検証の様々な結果が入っていることがわかります。
bst_rs.cv_results_.keys()性能の順位は、赤で囲った「rank_test_score」に入っているので、中身を見てみましょう。
性能の順位
キーから値を取得するには、dict型オブジェクトにキーを指定します。
bst_rs.cv_results_['rank_test_score']500回学習した結果なので、1から500までの順位(重複あり)が入っています。
性能評価の値
「mean_test_score」には、交差検証の性能評価が入っています。
4分割交差検証を行ったので、4回の平均値となります。
bst_rs.cv_results_['mean_test_score']
ハイパーパラメータの組み合わせ
「params」には、ランダムサーチでのハイパーパラメータの組み合わせが入っています。
bst_rs.cv_results_['params']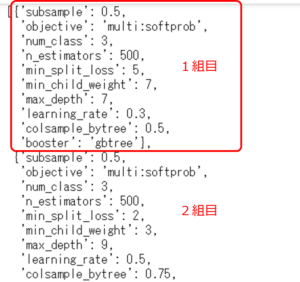
numpy配列からpandas.DataFrameの作成
個別にキーの値を確認したので、pandas.DataFrame(データフレーム)に入れてみましょう。
「rank_test_score」「mean_test_score」は、array([ 値 ])となっているので、numpy配列に入っています。
カラム名は、キーと同じ名前にして、pandas.DataFrameを作成します。
なお、pandas.DataFrameの表示は、display()関数を使用すると、表のレイアウトが保持されます。
# すべての評価結果をpandas.DataFrameに入れる
df_bst_rs = pd.DataFrame({'rank_test_score': bst_rs.cv_results_['rank_test_score'],
'mean_test_score':bst_rs.cv_results_['mean_test_score']})
display(df_bst_rs)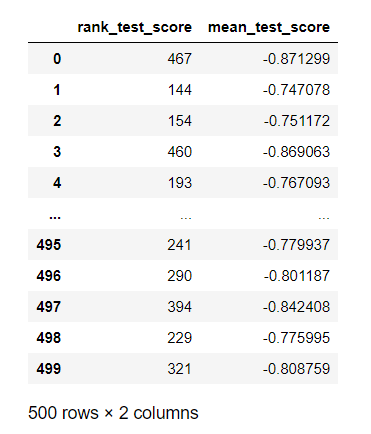
辞書(dict型オブジェクト)からpandas.DataFrameの作成
「params」は、[{ 値 }, { 値 }]となっているので、リストの中に辞書(dict型オブジェクト)が入っています。
各辞書のキーは同じなので、キーをカラム名にして、pandas.DataFrameを作成します。
# パラメータの組み合わせをpandas.DataFrameに入れる
df_rs_cv_results = pd.DataFrame(bst_rs.cv_results_['params'])
display(df_rs_cv_results)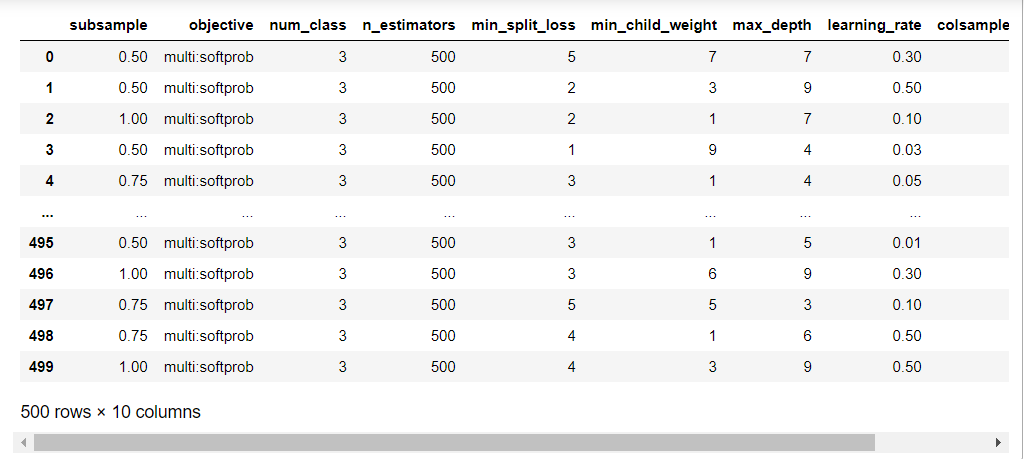
各カラム(列)に、各キーの値が並んでいます。
カラムの並び替え
元の記事では、カラムの並び替えは行っていませんが、ハイパーパラメータの設定順に変更してみます。
reindex()関数に、並び替えたカラム名のリストを与えます。
# カラムの並び替え
df_rs_cv_results = df_rs_cv_results.reindex(columns=['learning_rate', 'min_split_loss',
'max_depth', 'min_child_weight',
'subsample', 'colsample_bytree',
'n_estimators', 'objective',
'num_class', 'booster'])
display(df_rs_cv_results)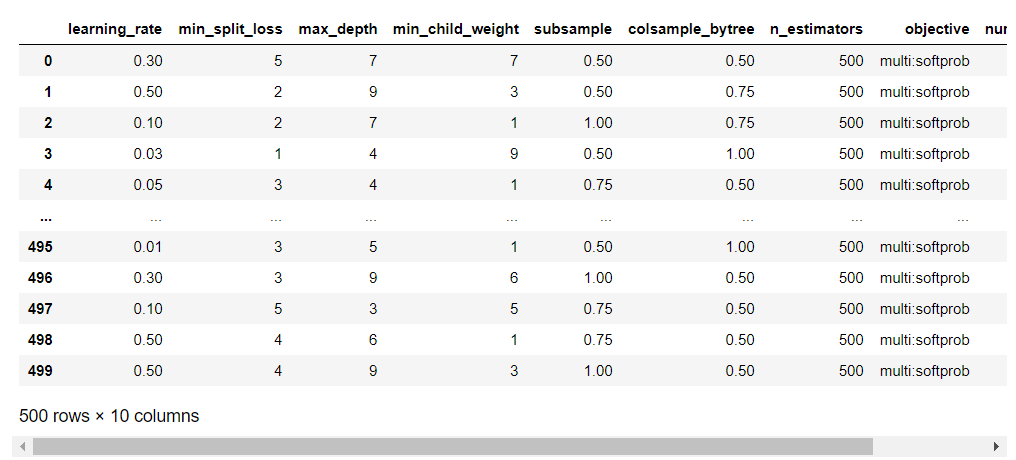
ハイパーパラメータの設定順に並び替えるひと手間で、格段に見やすくなりました。
pandas.DataFrameの結合
上記で作成した2個のpandas.DataFrameを横に結合します。
引数のaxis=1は、結合する軸を横に設定しています。
# 2つのpandas.DataFrameを横に結合する
df_bst_rs = pd.concat([df_bst_rs, df_rs_cv_results], axis=1)
display(df_bst_rs)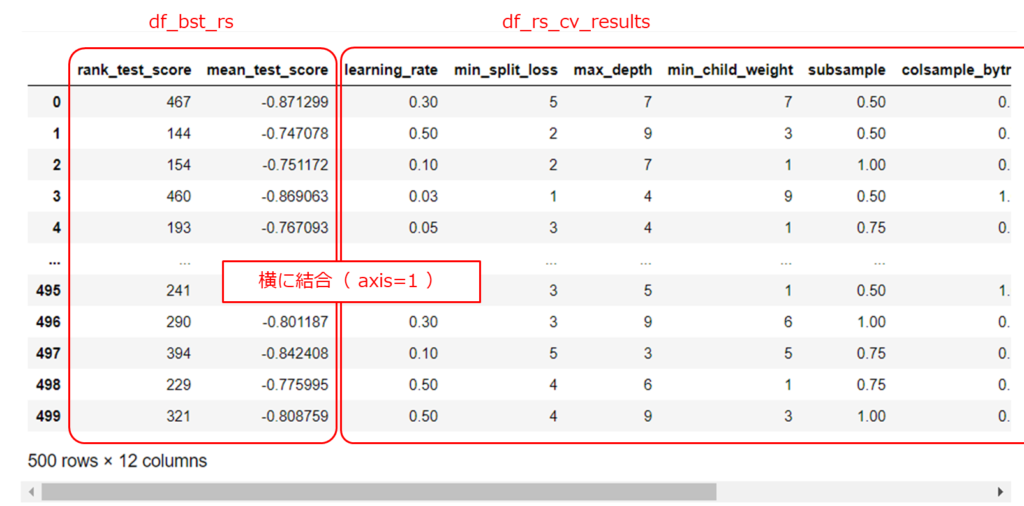
評価指標がよい順に並び替え
最後に、性能指標がよい順にするため、「rank_test_score」が昇順になるように並び替えます。
pandas.DataFrameのsort_values()メソッドを使うと、ソートされた新たなオブジェクトが返されます。
引数inplace=Trueとすると、元のオブジェクトが変更されます。
# 評価指標がよい順に並び替える
df_bst_rs.sort_values('rank_test_score', inplace=True)
上位10を表示
評価指標がよい順に並び替えられたので、上位10を見てみます。
# 上位10を表示
df_bst_rs.head(10)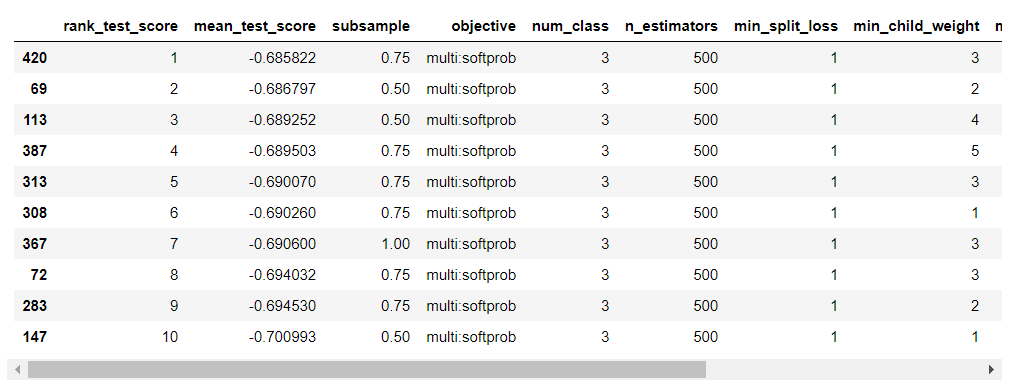
とても見やすい表ができました。
まとめ
Pandasを使って、データの整形作業を行いました。
グリッドサーチやランダムサーチには、それなりに時間を使うことになるので、「best_params_」をそのまま使うだけではもったいないです。
今回のようにデータを整形すれば、統計データを確認したり、グラフを作って傾向をつかむことも簡単です。
いろいろと手を動かしてみる一助になれば幸いです。

