
課題の設定
XGBoostは処理に時間がかかるため、単独で使用する機会は少ないのですが、LightGBMとアンサンブルすることもあるので、使い方をまとめておきたいと思います。
データセットの読込から学習過程の可視化まで、以下の作業をやってみます。
LightGBMについてまとめた以下の記事と同じ流れです。
重複する箇所もありますので、すでに読んでいただいた際はご了承ください。
【Python覚書】LigthGBMで多値分類問題を解いてみる
分析は、irisデータセットより大きなwineデータセットを使用します。
- データセットの読み込み
- 特徴量の作成
- パラメータの設定
- モデルの作成
- モデルの評価
- 学習過程の可視化
使用するライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn import datasetsXGBoostは、インストールされている前提でインポートしています。
インストールガイドは、以下(英語)にあります。
・Installation Guide
なお、インストール方法は、先人のブログがたくさんありますので、自身のPC環境に合った方法を探してみてください。
データセット
# wine データセットを読み込む
wine = datasets.load_wine()
X = wine['data']
y = wine['target']
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X = pd.DataFrame(X, columns=wine['feature_names'])sklearn.datasetsからwineデータセットを読み込みます。
読み込んだデータは、Bunch型のオブジェクトです。
print(type(wine))
>> <class 'sklearn.utils.Bunch'>Bunch型は、辞書型のサブクラスです。
辞書型と同じように、wine[‘key’]や、wine.keyで、要素を取りだすことができます。
なお、ドット表記の事例が多いようですが、この記事では、要素(特徴量)へのアクセスを明示するために、角括弧([ ])を使用します。
keyの一覧は、辞書のkeys()メソッドで取り出せます。
print(wine.keys())
>> dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])ここでは、説明変数 wine[‘data’]を変数X、目的変数 wine[‘target’]を変数yに格納しています。
変数Xは、各要素(特徴量)の名称 wine[‘feature_names’]をカラム名として、pandas.DataFrameに格納することで、pandasの強力なメソッドが使用できるようにします。
特徴量の作成
説明変数を確認します。
先頭の5行を取得します。
df_X.head()
irisよりカラムが多いので、表示が切れていますが、スクロールして確認できます。
なお、上の出力例は画像ですので、スクロールしません。
データフレームの次元は、shape属性で確認できます。
df_X.shape
>> (178, 13)178行×13列です。
infoメソッドでは、次元の他にも、各カラム名(Dtype)、非欠損値の数(Non-Null Count)、データ型(Dtype)などが確認できます。
df_X.info()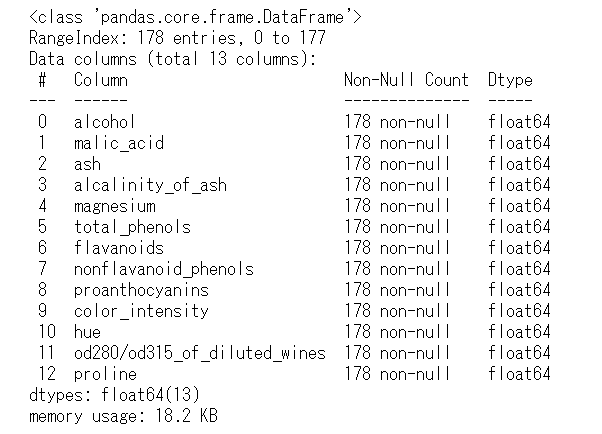
説明変数は、13つで、float64型の数値変数のみです。
その値は、連続する値の数値データで、カテゴリーやラベルを表すものはありません。
説明変数の説明は、以下の公式(英語)をご覧ください。
・scikit-learn(datasets)
LightGBMはカテゴリー変数を扱えますが、
残念ながら、XGBoostは、カテゴリー変数を扱えません。
この記事では、カテゴリー変数を使用しませんが、簡単に整理しておきます。
カテゴリー変数
カテゴリー変数の値には、性別(男・女)、信号機(赤・青・黄)など数値以外で表されるものと、チャンネル(1・2・8)、背番号(51・55・63)など数値で表されるものがありますが、その値は大小や順序を比較することはできません。
ラベルエンコーディング
XGBoostやLightGBMなどの機械学習では、カテゴリー変数の値は数値に変換して使用します。
例)男→0 ・ 女→1、赤→0 ・ 青→1 ・ 黄→2
このような変換を、ラベルエンコーディングと呼びます。
scikit-learnを使用して、ラベルエンコーディングをしてみます。
from sklearn.preprocessing import LabelEncoder
# カテゴリー変数
cat_val = ['赤', '青', '黄']
# LabelEncoderのインスタンスを生成
LE = LabelEncoder()
# ラベルを学習して、実行
cat_label = LE.fit_transform(cat_val)
# 表示
print(cat_label)
>> [0 1 2]LightGBMは、数値に変換したカテゴリー変数をcategorical_featuresに設定すると、カテゴリー値(大小に意味がない値)として扱うことができます。
XGBoostは、そのような設定がないので、更にOne-Hotエンコーディングやダミーエンコーディングを行う必要があります。
One-Hotエンコーディング
One-Hotエンコーディングでは、上の例では「赤・青・黄」の3つのラベルを新しい特徴量として変換します。
カラム「赤」(ラベルエンコーディング後はカラム「0」)は、値が赤のときは1、それ以外は0になります。カラム「青・黄」も同様です。
scikit-learnを使用して、One-Hotエンコーディングをしてみます。
from sklearn.preprocessing import OneHotEncoder
# OneHotEncoderのインスタンスを生成(sparse=Falseで、2次元のnumpy.ndarray)
OE = OneHotEncoder(sparse=False)
# ラベルを学習して、実行
cat_OneHot = OE.fit_transform(pd.DataFrame(cat_label))
print(cat_OneHot)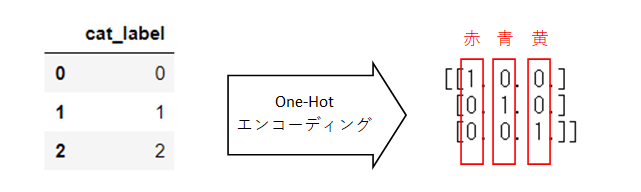
カテゴリー変数をOne-Hotエンコーディングできました。
ここで自由度の問題が指摘されます。
One-Hotエンコーディングで、新しく3つの特徴量を作成しました。
これを自由度k(=3)になっていると言い、3つの特徴量の各行のどこかに1があります。
ただ、3つの特徴量のうち、1つの特徴量を削除しても、残り2つの特徴量がすべて0になっていることで、なくなった特徴量は表現されます。
このように1つ特徴量が少ないことを、自由度k-1(=2)と言います。
本来、自由度k-1で十分なのに、自由度kにすると予測に問題が生じます。
One-Hotエンコーディングでは、1つの特徴量を削除する必要があります。
そのような、自由度k-1の特徴量を作成するのが、ダミーコーディングです。
ダミーコーディング
ダミーコーディングは、Pandasで実装されており、pandas.get_dummiesとして利用できます。
なお、デフォルトでは、k個のダミー変数に変換します(One-Hotエンコーディングと同じ)ので、引数drop_firstを設定します。
# カテゴリー変数
cat_val = ['赤', '青', '黄']
# ダミーコーディング(自由度k)
pd.get_dummies(cat_val)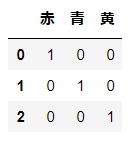
自由度kのダミーコーディング(One-Hotエンコーディング)ができました。
次に、自由度k-1のダミーコーディングをしてみます。
# カテゴリー変数
cat_val = ['赤', '青', '黄']
# ダミーコーディング(自由度k-1)
pd.get_dummies(cat_val, drop_first=True)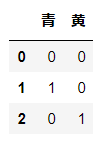
なお、カテゴリー変数をダミーコーディングすると、カテゴリーの数から1を引いた数の特徴量が作成されます。
膨大なカテゴリー数があるカテゴリー変数は、「特徴量ハッシング」など別の方法を取るほうがよいかもしれません。
モデルの作成
モデルの作成を、次のステップで行います。
1. 特徴量と目的変数を、XGBoost用のデータ構造に変換
2. ハイパーパラメーターの設定
3. 学習の実行
特徴量と目的変数を、XGBoost用のデータ構造に変換
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y,
test_size=0.2,
random_state=0,
stratify=y)
# 学習データを、学習用と検証用に分ける
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train,
test_size=0.2,
random_state=1,
stratify=y_train)
# カテゴリー変数
categorical_features = ['alcalinity_of_ash_per_unit']
# データを格納する
# 学習用
xgb_train = xgb.DMatrix(X_train, label=y_train)
# 検証用
xgb_eval = xgb.DMatrix(X_eval, label=y_eval)
# テスト用
xgb_test = xgb.DMatrix(X_test, label=y_test)ホールドアウト法(holdout cross-validation)
ホールドアウト法を使って、データセット全体を3つに分割します。
・学習データ
1. 学習用: モデルの学習に使用
2. 検証用: ハイパーパラメーターの調整に使用
・テストデータ: モデルの評価に使用

〇データセットの定義(呼び方、表記)について
今回、データセットを3つに分割しました。
この3つのデータセットは、出典によって、様々な表記がされているので注意が必要です。
一例ですが、以下のような感じです。
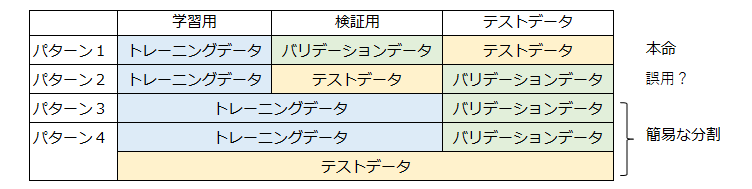
この記事は、パターン1に沿った表記にしています。
パターン3やパターン4は、トレーニングデータセットとテストデータセットの分割をしていないケースです。
テストデータセットを、トレーニングデータセットから独立させないで、バリデーションデータなどでモデルを評価します。
とりあえずモデルを動かしてみたい場合などの、簡易な取り扱いです。
〇train_test_split(df_X, y, test_size=0.2, random_state=0, stratify=y)
データ「df_X,y」をテストデータが20%になるように分割します。
パラメータ「random_state=0」は、分割に使用する乱数の初期値を固定します。
データセットの分け方によって、モデルの性能が上下するので、同じデータになるようにしています。
パラメータ「stratify=y」は、データ「y」の各要素が同じ数になるようにします。
今回は、分類を行うので、目的変数の分布が同じになるようにしています。
XGBoost用のデータセット
xgb.DMatrix()メソッドで、データセットを作成します。
ハイパーパラメーターの設定
xgb_params = {
'objective': 'multi:softprob', # 多値分類問題
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.1, # 学習率
'eval_metric': 'mlogloss' # 学習用の指標 (Multiclass logloss)
}今回は、多値分類を行うので、objectiveに「multi:softprob」を設定します。
なお、多値分類のobjectiveは2つあり、用途に合わせて使用します。
・multi:softprob : 各クラスに属する確率
・multi:softmax : 予測したクラス
評価関数metricは、「mlogloss」を使用します。
学習の実行
# 学習
evals = [(xgb_train, 'train'), (xgb_eval, 'eval')] # 学習に用いる検証用データ
evaluation_results = {} # 学習の経過を保存する箱
bst = xgb.train(xgb_params, # 上記で設定したパラメータ
xgb_train, # 使用するデータセット
num_boost_round=200, # 学習の回数
early_stopping_rounds=10, # アーリーストッピング
evals=evals, # 学習経過で表示する名称
evals_result=evaluation_results, # 上記で設定した検証用データ
verbose_eval=10 # 学習の経過の表示(10回毎)
)[0] train-mlogloss:0.96952 eval-mlogloss:0.98972
Multiple eval metrics have been passed: 'eval-mlogloss' will be used for early stopping.
Will train until eval-mlogloss hasn't improved in 10 rounds.
[10] train-mlogloss:0.33820 eval-mlogloss:0.44750
[20] train-mlogloss:0.14189 eval-mlogloss:0.30718
[30] train-mlogloss:0.07027 eval-mlogloss:0.25593
[40] train-mlogloss:0.04082 eval-mlogloss:0.23299
[50] train-mlogloss:0.02679 eval-mlogloss:0.22847
[60] train-mlogloss:0.01960 eval-mlogloss:0.22814
[70] train-mlogloss:0.01597 eval-mlogloss:0.22211
[80] train-mlogloss:0.01445 eval-mlogloss:0.21202
[90] train-mlogloss:0.01386 eval-mlogloss:0.20883
[100] train-mlogloss:0.01339 eval-mlogloss:0.20660
Stopping. Best iteration:
[99] train-mlogloss:0.01344 eval-mlogloss:0.20586num_boost_round=200
モデルの学習は、最大200回行います。
early_stopping_rounds=10
検証用のデータセットで、モデルの性能が10回改善されないと、学習がストップします。(アーリーストッピング)
evals=evals evals = [(xgb_train, ‘train’), (xgb_eval, ‘eval’)]
モデルの検証は、ホールドアウト法で行います。
左側のtrainが学習用データセットでの誤差評価、右側のevalが検証用データセットでの誤差評価です。
evaluation_results = {} evals_result=evaluation_results
evaluation_resultsに、学習の経過を保存します。
保存用の箱を用意して、メトリックの履歴を入れていきます。
verbose_eval=10
学習の経過を10回毎に表示させています。
なお、0に設定すると、学習経過が非表示になります。
補足
XGBoostには、上記のネイティブな書き方とは別に、scikit-learnに準拠した書き方があります。
model.fit(データセット)のときは、scikit-learnに準拠した書き方なので、注意してください。
モデルの評価
テストデータで予測
# テストデータで予測
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy の計算
acc = accuracy_score(y_test, y_pred_max)
print('Accuracy:', acc)Accuracy: 0.9722222222222222予測モデル
テストデータで予測します。
「bst.best_ntree_limit」は、アーリーストッピングが適用された99回です。
モデルは、99回目のハイパーパラメータで予測を行います。
多値分類、マルチクラス分類
# 小数点表示
np.set_printoptions(suppress=True)
print(y_pred)[[0.0014056 0.9970528 0.0015416 ]
[0.9918637 0.00420549 0.00393083]
[0.00297448 0.98445106 0.0125745 ]
[0.94947964 0.02277077 0.02774955]
[0.12047359 0.76232296 0.11720345]
以下、省略「y_pred」には、テストデータセットからモデルで予測した値が格納されています。
各列の値は、各クラスに属する0から1までの確率です。
各行の計は1になります。
1行目では、2列目のクラスに属する確率が99.70%となっています。
print(y_pred_max)[1 0 1 0 1 2 2 0 1 0 2 2 0 2 1 0 2 2 0 0 1 2 2 1 2 0 1 0 1 1 0 0 1 1 0 1]「y_pred_max」には、ターゲットのクラスが格納されています。
NumPyのargmax関数を使って、最も確率が高いクラスを予測クラスとしています。
1列目からカラムは「0, 1, 2」となっているので、先ほどの1行目では、2列目の「1」が予測クラスとなります。
なお、パラメーターの設定で「’objective’: ‘multi:softprob’」を
「’objective’: ‘multi:softmax’」にすると、「y_pred_max」と同じ値が得られます。
Accuracy(正答率)
scikit-learnのaccuracy_score()メソッドでAccuracy(正答率)を求めています。
また、テストデータのターゲットクラスと、予測クラスが一致する数を、ターゲットクラスの数で割ることでも、Accuracy(正答率)が求められます。(LightGBMの記事では、こちらを実装しています。)
今回のAccuracy(正答率)は、97.2%です。
多クラス分類の混同行列(confusion matrix)
混同行列(confusion matrix)は、クラス分類した結果を「本当のクラス」と「予測したクラス」をクロス集計したものです。
# 混同行列の計算
df_accuracy = pd.DataFrame({'va_y': y_test,
'y_pred_max': y_pred_max})
pd.crosstab(df_accuracy['va_y'], df_accuracy['y_pred_max'])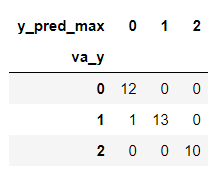
縦軸が「本当のクラス」で、横軸が「予測した」クラスです。
33個のテストデータのうち、1個を間違えており、本当は「1」のクラスを「0」と予測しています。
なお、scikit-learnのconfusion_matrix()メソッドでも、同様の結果が得られます。
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred_max))
こちらは、Numpyのndarrayとなります。
scikit-learnは、適合率や再現率、F1値などの評価指標を求めることもできます。
feature importance(特徴量の重要度)
# feature importanceを表示
xgb.plot_importance(bst)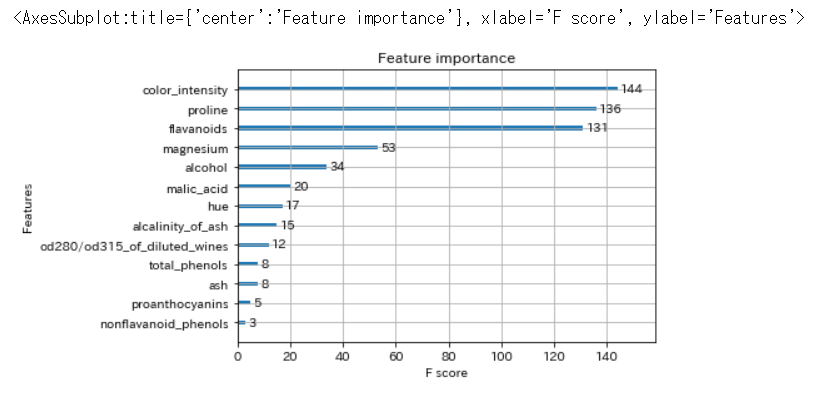
各特徴量が、どのくらい予測に寄与しているのかを確認できます。
学習過程の可視化
# 学習過程の可視化
plt.plot(evaluation_results['train']['mlogloss'], label='train')
plt.plot(evaluation_results['eval']['mlogloss'], label='eval')
plt.ylabel('Log loss')
plt.xlabel('Boosting round')
plt.title('Training performance')
plt.legend()
plt.show()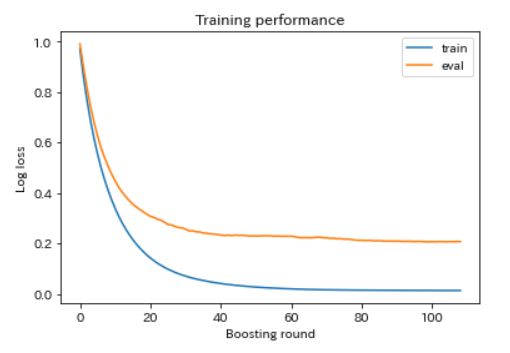
「evaluation_results」に格納しておいた学習過程を可視化します。
学習用と検証用に0.2くらいの乖離があります。
最も値が良かったのは、99回目のLogLoss 0.20586ですが、60回くらいで学習をやめてもよさそうです。
まとめ
XGBoostを使った多値分類の手順を紹介しました。
XGBoostは、カテゴリー変数のダミー変数化など、LIghtGBMより前処理が必要ですが、手軽に高い精度のモデルが作成できるので、いろいろ試してみてください。
この記事が学習の参考になれば幸いです。

