
課題の設定
XGBoostは、初期値のままでも高い予測性能がありますが、「ハイパーパラメーター」を調整することで、予測性能の向上が期待できます。
ハイパーパラメーターのチューニング自体は、scikit-learnの便利な関数を使うだけできます。
ただ、XGBoostでは、アーリーストッピングを使用して過学習にならないようすることも多いので、ハイパーパラメーターのチューニングも適切なタイミングでの値を得る必要があります。
この記事では、アーリーストッピングを併用した次の内容を解説します。
・グリッドサーチ
・ランダムサーチ
グリッドサーチ
グリッドサーチは、ハイパーパラメーターをチューニングする手法で、ハイパーパラメーターの値のリストを指定すると、しらみつぶしにすべての組み合わせでモデルの性能を評価して、最もよい性能となったハイパーパラメーターの値の組み合わせを取得します。
ここで大切なことは、XGBoostのようなブースティングの学習では、学習の回数によって性能が変わるので、ハイパーパラメーターによって適切な学習の回数を見極める必要があることです。
学習の回数もハイパーパラメーターとしてチューニング対象に含めることはできますが、値の候補は無数にあるので、適切な値を求めることは難しいです。
そこで、学習の回数についてはアーリーストッピングを使用して、評価しているハイパーパラメーターの性能が最もよくなるタイミングで比較する方法を取ります。
ランダムサーチ
ランダムサーチも、ハイパーパラメーターをチューニングする手法で、ハイパーパラメーターの値のリストを指定すると、設定した回数だけランダムに組み合わせてモデルの性能を評価し、その中で、最もよい性能となったハイパーパラメーターの値の組み合わせを取得します。
設定した回数で評価が終わるので、評価する値の数を増やして試行することができ、よい組み合わせの当たりをつけることができます。
分析の流れ
データセットの読込からハイパーパラメーターのチューニングまで、以下の作業をやってみます。
LightGBMやXGBoostについてまとめた以下の記事と同じ流れです。
今回は、XGBoostで交差検証をしていきます。
ハイパーパラメーターのチューニングを中心にまとめていきますので、その他の解説は上記の記事をご覧ください。
分析は、wineデータセットを使用します。
- データセットの読み込み
- 特徴量の作成
- ベースモデルの作成
- ランダムサーチ
- ハイパーパラメータのチューニング
- グリッドサーチ
- 再度、ハイパーパラメータのチューニング
使用するライブラリ
# モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn import datasetsデータセット
# wine データセットを読み込む
wine = datasets.load_wine()
X = wine['data']
y = wine['target']
# 説明変数をpandas.DataFrameに入れ、カラム名を付ける
df_X = pd.DataFrame(X, columns=wine['feature_names'])
# 使用する説明変数を、4個に絞る
df_X = df_X[['total_phenols', 'ash', 'proanthocyanins', 'nonflavanoid_phenols']]学習を難しくするため、wineデータセットで与えられる13個の説明変数を、4個に絞っています。
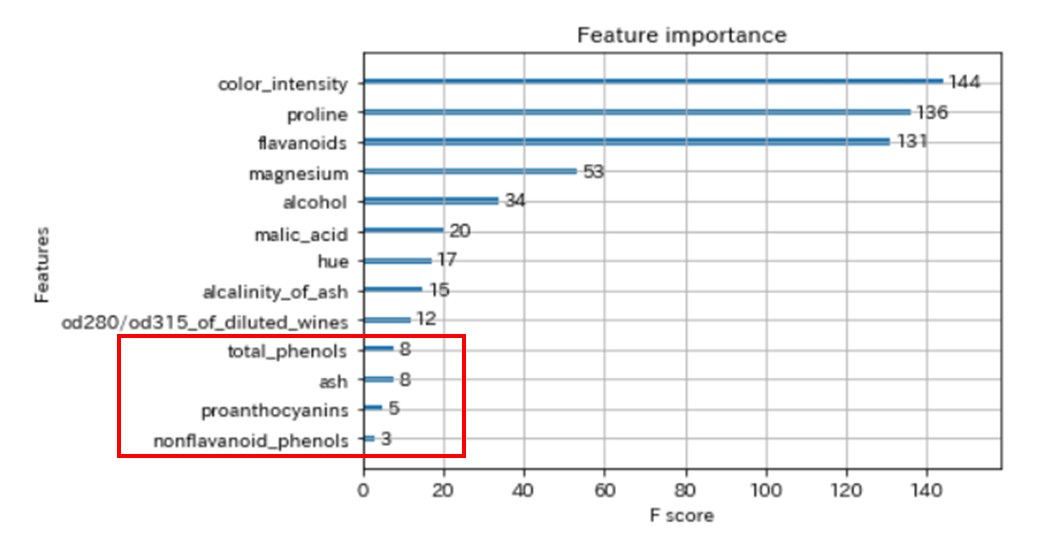
以下は、以前の記事でXGBoostの学習させたfeature importance(特徴量の重要度)です。
今回は、下から4個の特徴量を使用しています。
ベースラインモデルの作成
モデルの性能比較用に、ハイパーパラメーターを初期値にしたXGBoostのモデルを作成します。
XGBoostのモデル(ハイパーパラメーターは初期値)
# 学習データとテストデータに分ける
X_train, X_test, y_train, y_test = train_test_split(df_X, y,
test_size=0.2,
random_state=0,
stratify=y)
# 学習データを、学習用と検証用に分ける
X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train,
test_size=0.2,
random_state=2,
stratify=y_train)
# データを格納する
# テスト用
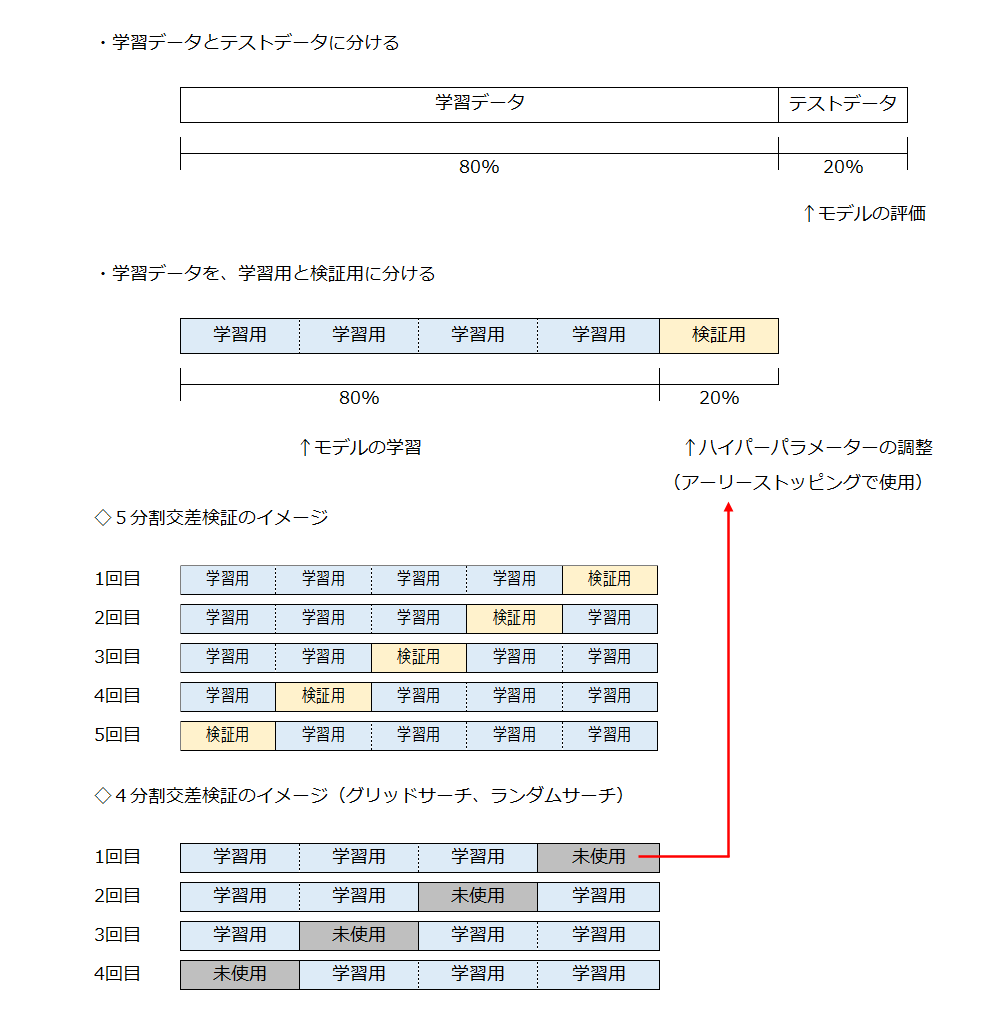
xgb_test = xgb.DMatrix(X_test, label=y_test)ここでは、以下のようにデータを分割しています。
学習データを使って、4分割交差検証を行った後、学習データから独立したテストデータを使って、モデルの性能を評価します。
これを、グリッドサーチは全ての組み合わせで行い、ランダムサーチでは設定した回数行います。
なお、今回はハイパーパラメーターのチューニング用に学習データから検証用の20%を取り出しています。
そのため、残りの学習用の80%を4分割交差検証(グリッドサーチ、ランダムサーチ)と5分割交差検証(性能評価)で使用しています。
これはイレギュラーなやり方で、通常の交差検証は学習データ(全体の80%)を使用します。
# 5-fold CVモデルの学習
# 5つのモデルを保存するリストの初期化
models = []
#accuracy、loglossを保存するNumPy配列の初期化
accuracies = np.array([])
loglosses = np.array([])
# 学習データの数だけの数列(0行から最終行まで連番)
row_no_list = list(range(len(y_train)))
# KFoldクラスをインスタンス化(これを使って5分割する)
K_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# KFoldクラスで分割した回数だけ実行(ここでは5回)
for train_cv_no, eval_cv_no in K_fold.split(row_no_list, y_train):
# ilocで取り出す行を指定
X_train_cv = X_train.iloc[train_cv_no, :]
y_train_cv = pd.Series(y_train).iloc[train_cv_no]
X_eval_cv = X_train.iloc[eval_cv_no, :]
y_eval_cv = pd.Series(y_train).iloc[eval_cv_no]
# 学習用
xgb_train = xgb.DMatrix(X_train_cv, label=y_train_cv)
# 検証用
xgb_eval = xgb.DMatrix(X_eval_cv, label=y_eval_cv)
# パラメータを設定
xgb_params = {
'objective': 'multi:softprob', # 多値分類問題
'num_class': 3, # 目的変数のクラス数
'eval_metric': 'mlogloss' # 学習用の指標 (Multiclass logloss)
}
# 学習
evals = [(xgb_train, 'train'), (xgb_eval, 'eval')] # 学習に用いる検証用データ
evaluation_results = {} # 学習の経過を保存する箱
bst = xgb.train(xgb_params, # 上記で設定したパラメーター
xgb_train, # 使用するデータセット
num_boost_round=500, # 学習の回数
early_stopping_rounds=10, # アーリーストッピング
evals=evals, # 上記で設定した検証用データ
evals_result=evaluation_results, # 上記で設定した箱
verbose_eval=0 # 学習の経過の表示(非表示)
)
# テストデータで予測する
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy を計算する
accuracy = sum(y_test == y_pred_max) / len(y_test)
#print('accuracy:', accuracy)
# Logloss を計算する
y_pred_ans = []
# 正解ラベルの確率
for i in range(len(y_pred)):
y_pred_ans.append(y_pred[i, y_test[i]])
logloss = -np.sum(np.log(y_pred_ans)) / len(y_pred_ans)
print('accuracy:', accuracy, 'logloss: ', logloss)
# 学習が終わったモデルをリストに入れておく
models.append(bst)
# 学習結果をNumPy配列に入れておく
accuracies = np.append(accuracies, accuracy)
loglosses = np.append(loglosses, logloss)
# 正解ラベルの確率とLogloss(平均値)
print('accuracy_ave: ', np.mean(accuracies), 'logloss_ave: ', np.mean(loglosses)) accuracy: 0.7777777777777778 logloss: 0.6255997021993002
accuracy: 0.7777777777777778 logloss: 0.7995079888237847
accuracy: 0.75 logloss: 0.682061513264974
accuracy: 0.8055555555555556 logloss: 0.4583887524074978
accuracy: 0.8333333333333334 logloss: 0.45962391959296334
accuracy_ave: 0.7888888888888889 logloss_ave: 0.6050363752577039評価指標に「Multiclass logloss」を使用して学習を行いました。
また、学習の回数は500回に設定していますが、検証用データで行う性能評価で、10回連続で指標が改善しないと学習をストップさせるアーリーストッピングを使用しています。
「Multiclass logloss」は、各クラスの確信度(合計1)を予測し、正解ラベルとどのくらい違っていたのかを示す指標です。
正答率(accuracy)は、モデルの予測が正解ラベルと一致しているかを示す指標です。
どちらもモデルの性能を測る指標となりますが、今回は「Multiclass logloss」を改善させることを目指します。
ランダムサーチの実装
ランダムサーチは、scikit-learnのRandomizedSearchCV関数を使用して行います。
RandomizedSearchCV
パラメータの詳細については、scikit-learnの公式サイトをご覧ください。
また、評価指標は、公式サイトのこちらです。
この記事の目玉においているXGBoostでランダムサーチとアーリーストッピングの併用することは、調べた限りではscikit-learnに実装されていないようです。
アーリーストッピングは実装されているのですが、交差検証の検証用データを取り出すことができません。
そのため、代替処置として、事前に取り出した検証用データを使用します(上図)。
学習に使用できるデータ量が少なくなるデメリットがあるものの、適切なタイミングで学習を終了できるメリットの方を取りたいと思います。
それでは、ランダムサーチを実行してみましょう。
# サンプリングするハイパーパラメータ
cv_params = {'objective':['multi:softprob'],
'num_class': [3],
'n_estimators':[500],
'booster': ['gbtree'],
'learning_rate':[0.01, 0.03, 0.05, 0.1, 0.3, 0.5], # default=0.3, range: [0,1]
'min_split_loss':[1, 2, 3, 4, 5], # default=0, range: [0,∞]
'max_depth':[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], # default=6, range: [0,∞]
'min_child_weight':[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], # default=1, range: [0,∞]
'subsample':[0.5, 0.75, 1.0], # default=1, range: [0,1]
'colsample_bytree':[0.5, 0.75, 1.0], # default=1, range: [0,1]
}
# 使用する推定器(分類)
bst = xgb.XGBClassifier()
# StratifiedKFoldでランダムサーチ
skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=42)
bst_rs = RandomizedSearchCV(bst, # 推定器(Estimator)
cv_params, # パラメータ
cv=skf, # 交差検証ジェネレーター
n_iter=500, # サンプリングする回数 500回
scoring="neg_log_loss", # 検証用データの予測を評価する指標
n_jobs=1, # 並行して実行するジョブの数
verbose=0)
bst_rs = bst_rs.fit(X_train, # 使用するデータセット
y_train,
early_stopping_rounds=10, # アーリーストッピング
eval_set=[(X_eval, y_eval)], # 学習に用いる検証用データ
eval_metric='mlogloss', # アーリーストッピングに使用する指標
verbose=0) # 学習の経過の表示(非表示)ハイパーパラメーターは、初期値を含め、設定できる範囲内で、複数個を選定しました。
この組み合わせを全て評価しようとすると、27,000種類もあり、交差検証で各4回を実行すると、膨大な時間がかかります。
今回は、サンプリングする回数を500回に設定したので、計算量は54分の1になります。
公式サイトにも記載があるとおり、実行回数と結果の品質はトレードオフの関係にありますが、とりあえず当たりが取れればいいと割り切っていきます。
なお、今回は、データ量が少ないので、かなり大きい実行回数を設定していても、数分で終わりますが、データ量が多く、1回の実行時間が長い場合は、1晩放置するようなことになるので、実行回数は慎重に設定してください。
ランダムサーチの結果
最もよかった評価指標を見てみます。
※ランダムな結果なので、以下は一例としてご覧ください。
print(bst_rs.best_score_)
>> -0.685822202757533評価指標は、Loglossなので、0に近いほどよい値となります。
最も評価指標がよかったハイパーパラメーターの組み合わせを見てみます。
print(bst_rs.best_params_){'subsample': 0.75, 'objective': 'multi:softprob', 'num_class': 3, 'n_estimators': 500, 'min_split_loss': 1, 'min_child_weight': 3, 'max_depth': 3, 'learning_rate': 0.03, 'colsample_bytree': 1.0, 'booster': 'gbtree'}では、このハイパーパラメーターの組み合わせを、ベースラインモデルと比べてみましょう。
パラメーターの詳細については、XGBoostの公式サイトをご覧ください。
# 5-fold CVモデルの学習
# 5つのモデルを保存するリストの初期化
models = []
#accuracy、loglossを保存するNumPy配列の初期化
accuracies = np.array([])
loglosses = np.array([])
# 学習データの数だけの数列(0行から最終行まで連番)
row_no_list = list(range(len(y_train)))
# KFoldクラスをインスタンス化(これを使って5分割する)
K_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# KFoldクラスで分割した回数だけ実行(ここでは5回)
for train_cv_no, eval_cv_no in K_fold.split(row_no_list, y_train):
# ilocで取り出す行を指定
X_train_cv = X_train.iloc[train_cv_no, :]
y_train_cv = pd.Series(y_train).iloc[train_cv_no]
X_eval_cv = X_train.iloc[eval_cv_no, :]
y_eval_cv = pd.Series(y_train).iloc[eval_cv_no]
# 学習用
xgb_train = xgb.DMatrix(X_train_cv, label=y_train_cv)
# 検証用
xgb_eval = xgb.DMatrix(X_eval_cv, label=y_eval_cv)
# パラメータを設定
xgb_params = {
'objective': 'multi:softprob', # 多値分類問題
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.03, # 学習率
'min_split_loss': 1, # 大きいほど保守的
'max_depth': 3, # 大きいほどモデルがより複雑
'min_child_weight': 3, # 大きいほど保守的
'subsample': 0.75, # サンプルするデータの比率
'colsample_bytree': 1.0, # サンプルする列の比率
'eval_metric': 'mlogloss' # 学習用の指標 (Multiclass logloss)
}
# 学習
evals = [(xgb_train, 'train'), (xgb_eval, 'eval')] # 学習に用いる検証用データ
evaluation_results = {} # 学習の経過を保存する箱
bst = xgb.train(xgb_params, # 上記で設定したパラメーター
xgb_train, # 使用するデータセット
num_boost_round=500, # 学習の回数
early_stopping_rounds=10, # アーリーストッピング
evals=evals, # 学習経過で表示する名称
evals_result=evaluation_results, # 上記で設定した検証用データ
verbose_eval=0 # 学習の経過の表示(非表示)
)
# テストデータで予測する
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy を計算する
accuracy = sum(y_test == y_pred_max) / len(y_test)
#print('accuracy:', accuracy)
# Logloss を計算する
y_pred_ans = []
# 正解ラベルの確率
for i in range(len(y_pred)):
y_pred_ans.append(y_pred[i, y_test[i]])
logloss = -np.sum(np.log(y_pred_ans)) / len(y_pred_ans)
print('accuracy:', accuracy, 'logloss: ', logloss)
# 学習が終わったモデルをリストに入れておく
models.append(bst)
# 学習結果をNumPy配列に入れておく
accuracies = np.append(accuracies, accuracy)
loglosses = np.append(loglosses, logloss)
print('accuracy_ave: ', np.mean(accuracies), 'logloss_ave: ', np.mean(loglosses)) accuracy: 0.75 logloss: 0.5434643957349989
accuracy: 0.7777777777777778 logloss: 0.49462609820895725
accuracy: 0.75 logloss: 0.5737502839830186
accuracy: 0.8055555555555556 logloss: 0.5435528225368924
accuracy: 0.8888888888888888 logloss: 0.4621267318725586
accuracy_ave: 0.7944444444444444 logloss_ave: 0.5235040664672852| ベースライン | ランダムサーチ | 備考 | |
| accuracy_ave: | 0.7888888888888889 | 0.7944444444444444 | 大きいほど良い |
| logloss_ave: | 0.6050363752577039 | 0.5235040664672852 | 小さいほど良い |
loglossが大幅に改善するとともに、正答率(accuracy)もわずかに良くなっています。
ランダムサーチで得られたハイパーパラメーター
ランダムサーチで性能評価の結果がよかった上位10の組み合わせを見てみましょう。
# すべての評価結果をpandas.DataFrameに入れる
df_bst_rs = pd.DataFrame({'rank_test_score': bst_rs.cv_results_['rank_test_score'],
'mean_test_score':bst_rs.cv_results_['mean_test_score']})
# パラメータの組み合わせをpandas.DataFrameに入れる
df_rs_cv_results = pd.DataFrame(bst_rs.cv_results_['params'])
# 2つのpandas.DataFrameを横に結合する
df_bst_rs = pd.concat([df_bst_rs, df_rs_cv_results], axis=1)
# 評価指標がよい順に並び替える
df_bst_rs.sort_values('rank_test_score', inplace=True)
# 上位10を表示
df_bst_rs.head(10)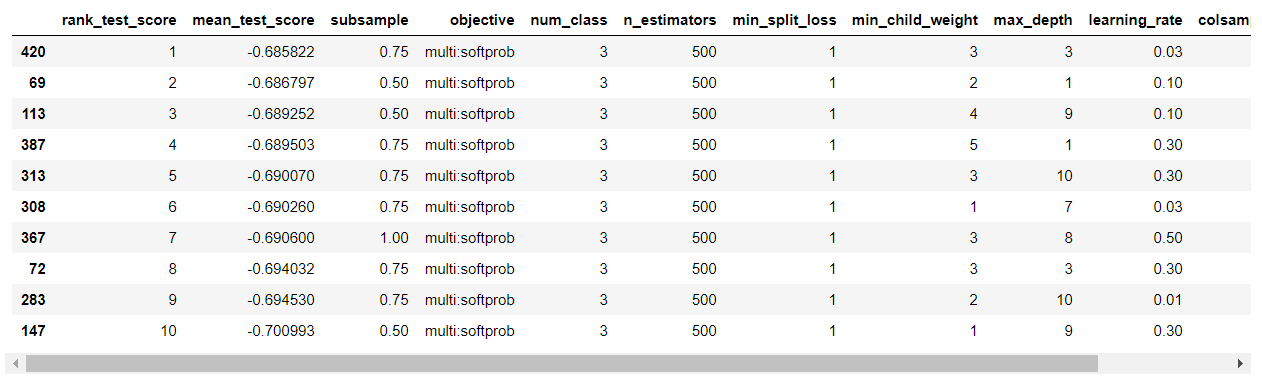
次に、グリッドサーチで使用するハイパーパラメーターの組み合わせは、この上位10で使用されてもので行います。
このコードの解説は、以下の記事をご覧ください。
【Python覚書】パラメーターチューニング:出力の活用(Pandasの使い方)
重複した値を除いて一覧にするには、pandas.DataFrameのunique()メソッドを使用します。
df_bst_rs.head(10)['learning_rate'].unique()array([0.03, 0.1 , 0.3 , 0.5 , 0.01])アーリーストッピング
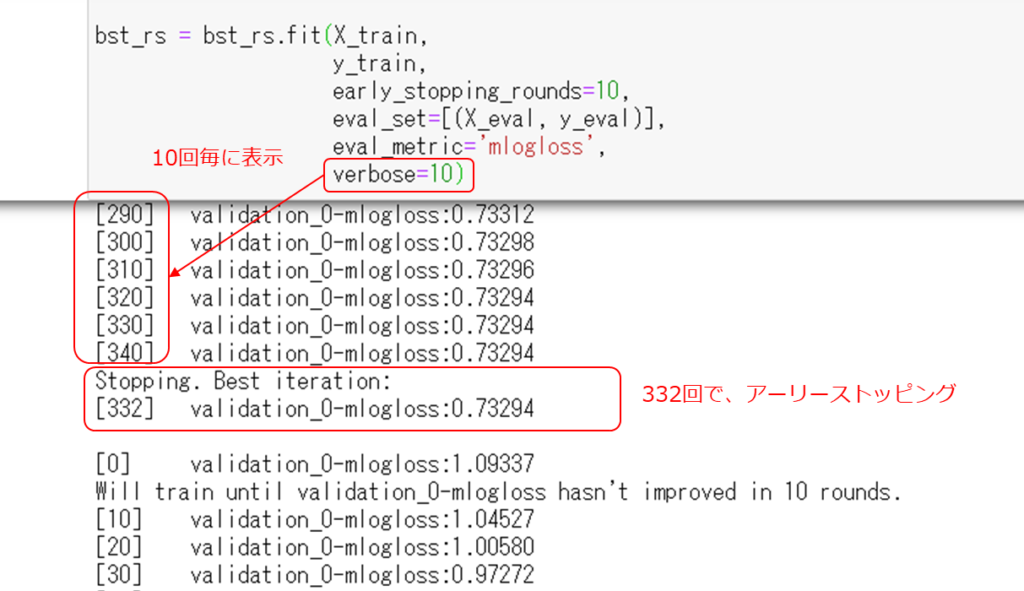
ランダムサーチを実行するときに、学習の経過を非表示にしているので、アーリーストッピングが働いていることを確認できません。
以下のように、verboseパラメータを変更すると、学習を10回実行する毎にメッセージが表示され、アーリーストッピングが働いていることがわかります。
また、学習の上限回数に設定した500回以内で学習を終えていることもわかります。
上限回数はすごく大きくしておくか、試行的に学習の経過を観察して、適切な値を見つけると良いと思います。
グリッドサーチの実装
グリッドサーチは、scikit-learnのGridSearchCV関数を使用して行います。
GridSearchCV
パラメーターの詳細については、scikit-learnの公式サイトをご覧ください。
また、ランダムサーチと同じですが、評価指標は、公式サイトのこちらです。
なお、ランダムサーチと同様に、アーリーストッピングには、事前に取り出した検証用データを使用します(上図)。
cv_params = {'objective':['multi:softprob'],
'num_class': [3],
'n_estimators':[500],
'booster': ['gbtree'],
'learning_rate':[0.01, 0.03, 0.1, 0.3, 0.5],
'min_split_loss':[1],
'max_depth':[1, 3, 7, 8, 9, 10],
'min_child_weight':[1, 2, 3, 4, 5],
'subsample':[0.5, 0.75, 1.0],
'colsample_bytree':[0.5, 0.75, 1.0]
}
bst = xgb.XGBClassifier()
# StratifiedKFoldでグリッドサーチ
skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=42)
bst_grid = GridSearchCV(bst, # 推定器(Estimator)
param_grid=cv_params, # パラメータ
cv=skf, # 交差検証ジェネレーター
scoring="neg_log_loss", # 検証用データの予測を評価する指標
n_jobs=1, # 並行して実行するジョブの数
verbose=0) # 学習の経過の表示(非表示)
bst_grid = bst_grid.fit(X_train, # 使用するデータセット
y_train,
early_stopping_rounds=10, # アーリーストッピング
eval_set=[(X_eval, y_eval)], # 学習に用いる検証用データ
eval_metric='mlogloss', # アーリーストッピングに使用する指標
verbose=0) # 学習の経過の表示(非表示)ハイパーパラメーターは、ランダムサーチで得られた上位10の組み合わせに使用されたものです。
ランダムサーチによって、27,000種類の組み合わを、1,350種類に絞り込んだことになります。
グリッドサーチサーチの結果
最もよかった評価指標を見てみます。
print(bst_grid.best_score_)
>> -0.6624305092573644評価指標は、Loglossなので、0に近いほどよい値となります。
最も評価指標がよかったハイパーパラメーターの組み合わせを見てみます。
print(bst_grid.best_params_){'booster': 'gbtree', 'colsample_bytree': 1.0, 'learning_rate': 0.3, 'max_depth': 3, 'min_child_weight': 2, 'min_split_loss': 1, 'n_estimators': 500, 'num_class': 3, 'objective': 'multi:softprob', 'subsample': 0.75}では、このハイパーパラメーターの組み合わせを、ベースラインモデルと比べてみましょう。
# 5-fold CVモデルの学習
# 5つのモデルを保存するリストの初期化
models = []
#accuracy、loglossを保存するNumPy配列の初期化
accuracies = np.array([])
loglosses = np.array([])
# 学習データの数だけの数列(0行から最終行まで連番)
row_no_list = list(range(len(y_train)))
# KFoldクラスをインスタンス化(これを使って5分割する)
K_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# KFoldクラスで分割した回数だけ実行(ここでは5回)
for train_cv_no, eval_cv_no in K_fold.split(row_no_list, y_train):
# ilocで取り出す行を指定
X_train_cv = X_train.iloc[train_cv_no, :]
y_train_cv = pd.Series(y_train).iloc[train_cv_no]
X_eval_cv = X_train.iloc[eval_cv_no, :]
y_eval_cv = pd.Series(y_train).iloc[eval_cv_no]
# 学習用
xgb_train = xgb.DMatrix(X_train_cv, label=y_train_cv)
# 検証用
xgb_eval = xgb.DMatrix(X_eval_cv, label=y_eval_cv)
# パラメータを設定
xgb_params = {
'objective': 'multi:softprob', # 多値分類問題
'num_class': 3, # 目的変数のクラス数
'learning_rate': 0.3 , # 学習率
'min_split_loss': 1, # 大きいほど保守的
'max_depth': 3, # 大きいほどモデルがより複雑
'min_child_weight': 2, # 大きいほど保守的
'subsample': 0.75, # サンプルするデータの比率
'colsample_bytree': 1.0, # サンプルする列の比率
'eval_metric': 'mlogloss' # 学習用の指標 (Multiclass logloss)
}
# 学習
evals = [(xgb_train, 'train'), (xgb_eval, 'eval')] # 学習に用いる検証用データ
evaluation_results = {} # 学習の経過を保存する箱
bst = xgb.train(xgb_params, # 上記で設定したパラメーター
xgb_train, # 使用するデータセット
num_boost_round=500, # 学習の回数
early_stopping_rounds=10, # アーリーストッピング
evals=evals, # 学習経過で表示する名称
evals_result=evaluation_results, # 上記で設定した検証用データ
verbose_eval=0 # 学習の経過の表示(非表示)
)
# テストデータで予測する
y_pred = bst.predict(xgb_test, ntree_limit=bst.best_ntree_limit)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy を計算する
accuracy = sum(y_test == y_pred_max) / len(y_test)
#print('accuracy:', accuracy)
# Logloss を計算する
y_pred_ans = []
# 正解ラベルの確率
for i in range(len(y_pred)):
y_pred_ans.append(y_pred[i, y_test[i]])
logloss = -np.sum(np.log(y_pred_ans)) / len(y_pred_ans)
print('accuracy:', accuracy, 'logloss: ', logloss)
# 学習が終わったモデルをリストに入れておく
models.append(bst)
# 学習結果をNumPy配列に入れておく
accuracies = np.append(accuracies, accuracy)
loglosses = np.append(loglosses, logloss)
print('accuracy_ave: ', np.mean(accuracies), 'logloss_ave: ', np.mean(loglosses)) accuracy: 0.8055555555555556 logloss: 0.4985087712605794
accuracy: 0.8333333333333334 logloss: 0.4715306493971083
accuracy: 0.8055555555555556 logloss: 0.5427776442633735
accuracy: 0.7777777777777778 logloss: 0.5028862423366971
accuracy: 0.8333333333333334 logloss: 0.46409760581122506
accuracy_ave: 0.8111111111111111 logloss_ave: 0.4959601826137966| ベースライン | ランダムサーチ | グリッドサーチ | 備考 | |
| accuracy_ave: | 0.788889 | 0.794444 | 0.811111 | 大きいほど良い |
| logloss_ave: | 0.605036 | 0.523504 | 0.495960 | 小さいほど良い |
結果は、小数点以下7位で四捨五入しています。
loglossが更に改善するとともに、正答率(accuracy)も良くなっています。
グリッドサーチで得られたハイパーパラメーター
ランダムサーチで性能評価の結果がよかった上位10の組み合わせを見てみましょう。
# すべての評価結果をpandas.DataFrameに入れる
df_bst_grid = pd.DataFrame({'rank_test_score': bst_grid.cv_results_['rank_test_score'],
'mean_test_score':bst_grid.cv_results_['mean_test_score']})
# パラメータの組み合わせをpandas.DataFrameに入れる
df_cv_results = pd.DataFrame(bst_grid.cv_results_['params'])
# 2つのpandas.DataFrameを横に結合する
df_bst_grid = pd.concat([df_bst_grid, df_cv_results], axis=1)
# 評価指標がよい順に並び替える
df_bst_grid.sort_values('rank_test_score', inplace=True)
# 上位10を表示
df_bst_grid.head(10)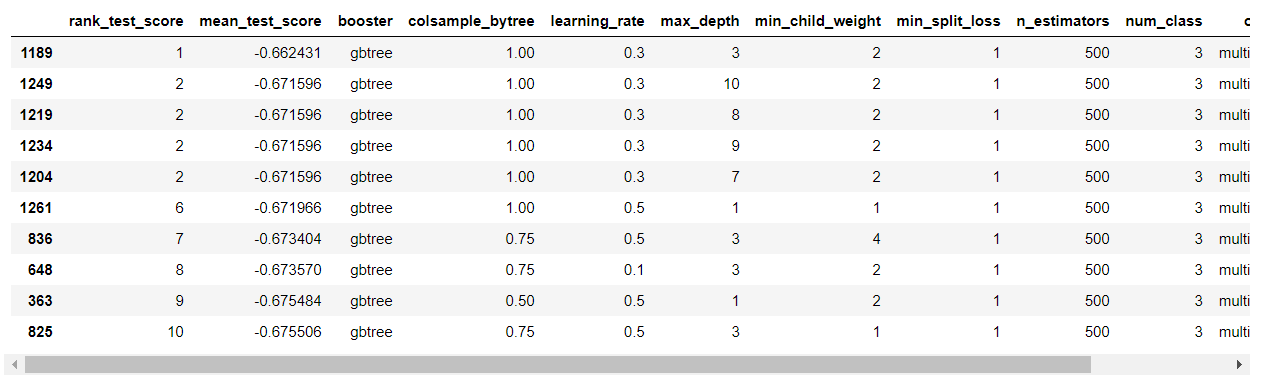
上位5は、max_depthの値が違うだけで、残りのハイパーパラメーターの値は同じです。
max_depthの値は、グリッドサーチでは[2, 4]をはずしているので、再度、max_depthだけを動かすグリッドサーチをしてみると、更に良い結果が得られるかもしれません。
まとめ
アーリーストッピングを併用したランダムサーチとグリッドサーチを行い、ハイパーパラメーターをチューニングしました。
データを無駄にしてしまう実装ですが、予測性能の向上を図ることができました。
なお、ハイパーパラメーターのチューニングは大切ですが、きちんと特徴量を作ることが先決だと思いますので、ほどほどに取り組んでください。

